
OmniTalker
 1.75w
1.75w 0
0 0
0
OmniTalker是阿里通义实验室开发的一款基于深度学习和多模态融合技术的新型数字人视频生成大模型。它能够通过上传一段参考视频,实现对视频中人物的表情、声音和说话风格的精准模仿,从而生成高度逼真的数字人视频。
直达网站
工具介绍
OmniTalker是什么?
OmniTalker是阿里通义实验室开发的一款基于深度学习和多模态融合技术的新型数字人视频生成大模型。它能够通过上传一段参考视频,实现对视频中人物的表情、声音和说话风格的精准模仿,从而生成高度逼真的数字人视频。
主要亮点
- 精准模仿能力:OmniTalker能够捕捉到参考视频中人物的细微表情和声音特点,生成与之高度相似的音视频内容,让人难以分辨真假。
- 降低成本:相较于传统的数字人制作流程,OmniTalker显著降低了制作成本,使得更多用户能够轻松拥有高质量的数字人服务。
- 增强真实感与互动体验:生成的音视频内容真实感极强,且由于能够精准模仿人物的声音和说话风格,为用户提供了更加自然、流畅的互动体验。
模型优势
- 多模态融合:OmniTalker实现了音频、视频和文本的多模态融合,使得生成的数字人更加生动、立体。
- 高效处理:模型采用先进的算法和架构,能够高效处理大量数据,快速生成高质量的音视频内容。
- 零样本学习:OmniTalker具备零样本学习能力,只需一段参考视频即可生成新的数字人视频,无需额外训练数据。
需求人群
- 内容创作者:如视频博主、主播等,可以利用OmniTalker快速生成高质量的数字人视频内容。
- 企业用户:企业可以利用OmniTalker制作虚拟客服、虚拟代言人等数字人形象,提升品牌形象和用户体验。
- 教育机构:教育机构可以利用OmniTalker制作虚拟教师、虚拟助教等数字人形象,为学生提供更加生动、有趣的学习体验。
适用场景
- 虚拟主播:利用OmniTalker生成虚拟主播形象,进行直播、录播等节目制作。
- 虚拟客服:企业可以利用OmniTalker制作虚拟客服形象,为用户提供24小时不间断的在线服务。
- 游戏与娱乐:在游戏和娱乐领域,OmniTalker可以生成虚拟角色形象,为玩家提供更加沉浸式的游戏体验。
使用便捷性
OmniTalker的使用非常简便。用户只需在平台上上传一段参考视频,选择相应的模板和参数设置,即可快速生成与之同步的音频和视频内容。目前,该项目已在魔搭社区和HuggingFace等平台开放体验,并提供了详细的教程和示例视频供用户参考。
OmniTalker如何使用
- 注册与登录:用户需要访问OmniTalker的官方网站或相关平台(如魔搭社区、HuggingFace等)进行注册和登录。
- 上传参考视频:在平台上上传一段清晰的参考视频,确保视频中的人物表情、声音和说话风格清晰可辨。
- 选择模板与参数:根据需求选择合适的模板和参数设置,如视频分辨率、帧率、音频质量等。
- 生成与导出:点击生成按钮,等待模型处理完成后即可导出生成的音视频内容。
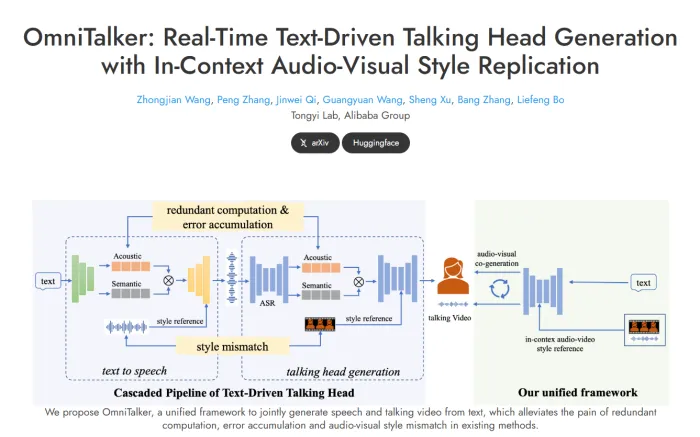
技术背景与突破
近年来,随着语言大模型和生成式AI的迅猛发展,虚拟主播和虚拟助手的应用越来越广泛。然而,传统的文本驱动数字人生成研究相对较少,且存在音画不同步、说话风格不一致等问题。OmniTalker通过引入双分支DiT架构和多模态特征融合技术,成功克服了这些技术瓶颈,实现了从文本和参考视频中同时生成同步的语音和视频。
模型结构与创新
OmniTalker的模型结构由三大核心部分构成:
- 特征提取模块:负责提取音频特征和视觉特征,并确保两者在时间上的完美同步。
- 多模态特征融合模块:将音频特征和视觉特征进行融合,提升音视频内容的整合效果。
- 解码器模块:经过预训练的解码器能够高效将合成的音视频特征转换为原始格式,保证输出的高质量。
此外,OmniTalker还采用了先进的Flow Matching训练技巧和优化算法,进一步提升了模型的性能和生成效果。
实验数据与表现
通过实验数据的对比和分析,OmniTalker在音频生成和视觉效果方面都表现出色。它显示出更低的错误率、更高的声音相似度和更逼真的视觉效果。特别是在零样本条件下,OmniTalker依然能够保持出色的生成效果,进一步证明了其强大的泛化能力和实用性。
未来发展
总的来说,阿里通义实验室推出的这款OmniTalker模型无疑是数字人生成领域的一大创新。它不仅降低了制作成本、提升了生成内容的真实感和互动体验,还为用户提供了更加简便、高效的使用方式。随着技术的不断进步和应用场景的不断拓展,相信OmniTalker将会在更多领域得到广泛应用,并为用户带来更加丰富的数字人体验。未来,我们期待OmniTalker能够继续引领数字人生成领域的发展潮流,为人工智能技术的进步贡献更多的力量。
评论
全部评论

暂无评论
热门推荐










相关推荐

Qwen Chat
Qwen Chat是阿里通义千问团队推出的一个集成多种Qwen AI大模型的Web UI界面,它为用户提供了一个强大且高效的AI交互平台。该平台基于先进的AI技术,集成了多种Qwen AI大模型,旨在为用户提供丰富多样的功能,以满足不同场景下的需求。
小米MiMo-7B
MiMo-7B是小米AI实验室发布的首个专为推理(Reasoning)设计的开源大模型,该模型以7亿参数的轻量化架构,结合强化学习优化,展现了在数学、代码和通用推理任务上的卓越性能,甚至超越了多个32亿参数以上的基线模型。
Nova Sonic
Nova Sonic是亚马逊近期推出的一款新一代AI语音模型,旨在进一步提升其语音助手Alexa+的性能。这款模型通过整合语音理解和生成的能力,为用户带来更加自然流畅的对话体验。Nova Sonic的推出,标志着亚马逊在语音识别技术领域再次取得了重大突破。
面壁露卡
「面壁露卡 Luca」是面壁智能基于自研千亿参数基座模型 CPM 打造的多模态智能对话助手。
CogView4
CogView4是智谱AI推出的开源中文文生图模型。CogView4 的参数规模精准布局至 6 亿,这一参数规模,为模型构建了一个庞大且高效的 “智慧中枢”,赋予其极为强大的运算和学习能力。还全面支持中文输入和中文文本到图像的生成,被称其为“首个能在画面中生成汉字的开源模型”
天工AI大模型
昆仑万维天工AI大模型是昆仑万维集团自主研发的一系列大型语言模型(LLMs),旨在通过先进的自然语言处理和深度学习技术,为用户提供高效、智能的服务和体验。该系列模型不仅具备强大的语言理解和生成能力,还广泛应用于教育、企业客服、新闻媒体、创意产业、医疗、法律咨询、金融服务等多个行业。
火山方舟
火山方舟是火山引擎旗下的大模型服务平台,定位为面向企业提供全面的模型即服务(MaaS,Model-as-a- Service)解决方案。它汇聚百川智能、出门问问、复旦大学MOSS、IDEA研究院、澜舟科技、MiniMax、智谱AI等多家 AI 科技公司及科研院所的大模型,打破模型资源分散的局面。
Seele AI
Seele AI是由全灵(深圳)人工智能有限公司推出的全球首个端到端AI生成3D游戏的多模态大模型,它以自然语言为驱动,支持文本、语音、图片、视频等多模态输入,可一键生成包含角色、场景、玩法逻辑、物理规则、动画音效等全要素的完整3D游戏世界,实现“零代码”创作与动态迭代优化。
0
0
欢迎来到AI Top100!我们聚合全球500+款AI智能软件,提供最新资讯、热门课程和活动。我们致力于打造最专业的信息平台,让您轻松了解全球AI领域动态,并为您提供优质服务。
合作伙伴



