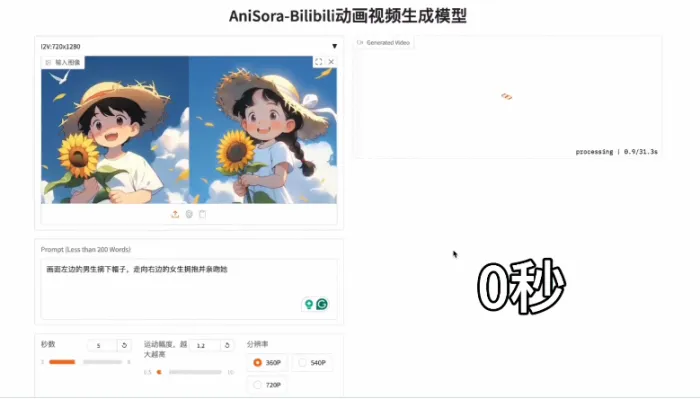

AniSora
 1.82w
1.82w 0
0 0
0
Bilibili(B站)的开源动漫视频生成模型AniSora是专为动漫视频生成设计的综合系统,该模型具备海量数据支持、时空掩码技术、专业评估体系三大核心优势,可一键生成多种动漫风格的视频内容,显著降低创作门槛并提升制作效率。
直达网站
工具介绍

一、AniSora是什么?
AniSora是B站团队基于IJCAI 2025接收的论文成果开发的开源动漫视频生成系统,其技术定位可概括为:
- 专为二次元内容优化:针对动漫独特的艺术风格(如日漫、国漫、美漫)、夸张动作(如超高速移动、非物理变形)及多样化场景(番剧、VTuber表演、鬼畜动画)设计,突破传统模型在动漫生成中的局限性。
- 全链路可控生成:通过时空掩码模块实现图像到视频、帧插值、局部区域引导等核心功能,支持从单张图片生成连贯动画,或对已有视频进行精准编辑。
- 开源生态构建:提供完整训练代码、预训练模型及评估基准,支持在RTX 4090等消费级硬件上部署,降低技术门槛,促进社区协作。
二、核心能力:
1. 千万级数据处理流水线
- 数据规模:整合超过1000万条高质量文本-视频配对数据,覆盖中、日、美三大动画流派,涵盖番剧、国创、漫画改编、VTuber内容等30余个场景。
- 数据预处理:通过视频时空特征提取、字幕与水印移除等技术,确保数据质量,避免生成伪影(如乱码字幕)。
2. 时空掩码可控生成模型
- 图生视频(Image-to-Video):上传单张图片即可生成连贯动态视频,支持自定义角色动作、镜头运动(如缩放、旋转)。
- 帧插值(Frame Interpolation):在关键帧间智能插入中间帧,实现平滑过渡,支持首尾帧引导、多帧插值等模式,减少手工绘制工作量。
- 局部图像引导(Localized Motion Control):通过遮罩技术精准控制特定区域(如角色面部、肢体)的运动,结合前景检测与目标跟踪,实现复杂动作编辑。
- 技术框架:基于Masked Diffusion Transformer,采用3D Causal VAE编码时空特征,结合3D-RoPE(三维相对位置编码)与全局注意力机制,提升动态一致性与细节保真度。
3. 强化学习优化与评估体系
- AnimeReward系统:构建高质量奖励数据集,通过人类偏好对齐(RLHF)优化生成内容的自然度与观感。
- 评估基准:发布包含948段动画视频的评测数据集,通过双盲人评实验与VBench测试,在人物一致性、运动流畅性等维度达到SOTA(行业领先水平)。

三、需求人群:
- 动画工作室与独立创作者:快速生成高质量动画片段,降低制作成本(如传统手绘需数周完成的分镜,AniSora可实时生成)。
- 虚拟主播(VTuber)运营团队:生成舞蹈、表演等动态视频,丰富直播内容,提升观众互动。
- 漫画IP孵化方:将静态漫画快速转化为动画,拓展IP价值(如《一人之下》等国漫IP可通过AniSora生成PV宣传片)。
- 教育机构与学习者:作为教学工具,帮助学生掌握动画制作技巧(如通过局部引导功能理解运动规律)。
- 营销与娱乐内容团队:生成动画广告、社交媒体短视频,提升传播效果(如品牌方可快速制作二次元风格产品宣传片)。
四、应用场景:
1. 动画制作
- 案例:某小型动画工作室使用AniSora生成番剧《灵笼》的战斗场景,通过图生视频功能将概念图转化为动态视频,结合帧插值优化动作流畅性,制作周期缩短60%。
- 优势:支持多风格生成(如2D手绘、3D建模),适配不同项目需求。
2. VTuber内容创作
- 案例:虚拟主播“琉绮Ruki”利用AniSora生成舞蹈表演视频,通过局部引导功能精准控制角色肢体动作,实现与观众实时互动。
- 优势:降低内容制作门槛,提升直播吸引力。
3. 漫画改编与IP孵化
- 案例:快看漫画使用AniSora将《偷偷藏不住》改编为动态漫画,通过帧插值技术优化角色对话场景,用户留存率提升35%。
- 优势:快速验证IP市场潜力,降低试错成本。
4. 教育与培训
- 案例:中国传媒大学动画学院将AniSora引入教学,学生通过局部引导功能实践“角色口型同步”技术,学习效率提升50%。
- 优势:提供低成本、高效率的实践工具。
5. 营销与娱乐
- 案例:某品牌通过AniSora生成二次元风格产品广告,结合强化学习优化视觉风格,用户点击率提升40%。
- 优势:满足年轻用户对个性化内容的需求。
五、如何使用AniSora?
1. 本地部署(以AniSora V1.0为例)
硬件要求:4张RTX 4090显卡(或等效算力设备)。
步骤:
- 创建虚拟环境:使用Miniconda安装Python 3.10,并激活环境。
- 克隆仓库:从GitHub下载项目代码(
git clone https://github.com/bilibili/Index-anisora.git)。 - 安装依赖:修改
requirements.txt中的pyav为av,并执行pip install -r requirements.txt。 - 下载模型:从HuggingFace或ModelScope下载预训练权重(如
CogVideoX_VAE_T5、5B模型权重),并放置于指定目录。 - 模型推理:运行
python demo.py --base configs/cogvideox/cogvideox_5b_720_169_2.yaml生成视频。
2. 开发接口与插件扩展
- API支持:提供RESTful API,开发者可通过HTTP请求调用模型生成视频。
- 插件生态:支持自定义插件开发(如连接企业微信、数据库查询),扩展应用场景。
六、行业影响:
1. 技术普惠:降低创作门槛
- 零代码开发:业务人员可通过自然语言描述快速生成视频,无需专业编程技能。
- 硬件适配:与昆仑芯合作推出“文心一体机”,推理延迟降至10毫秒,支持本地化部署,满足金融、政务等高安全需求场景。
2. 生态闭环:从开发到变现的全链路支持
- 流量分发:智能体可一键部署至B站搜索、文心一言App、小度音箱等10余个渠道,日均触达用户超5亿。
- 商业变现:提供订阅制、按需付费等模式,某教育机构通过付费问答功能实现月收入超20万元。
3. 全球化布局:推动中国AI标准输出
- 多语言支持:平台已支持中英文双语开发,并与IBM、蓝美视讯等国际企业合作,在东南亚、欧洲市场落地“存储+AI”解决方案。
- 开源协作:通过GitHub等平台吸引全球开发者贡献代码,加速技术迭代。
AniSora,开启AI动漫普惠新时代
AniSora的开源不仅是B站在AI领域的技术突破,更是对动漫创作生态的重构。从降低制作门槛的零代码工具,到覆盖全场景的智能体解决方案,AniSora正在让每个个体都能参与到AI创新中。
未来,随着多模态感知、MCP协议等技术的成熟,智能体将进一步跨越“可用”与“好用”的门槛,成为连接物理世界与数字世界的核心纽带。AniSora,正以开放、协同的姿态,携手全球开发者共同迈向AGI(通用人工智能)的星辰大海。
想了解AITOP100平台其它版块的内容,请点击下方超链接查看
AI创作大赛 | AI活动 | AI工具集 | AI资讯专区
AITOP100平台官方交流社群二维码:

评论
全部评论

暂无评论
热门推荐








相关推荐

豆蔻妇科大模型
豆蔻妇科大模型由壹生检康(杭州)生命科技有限公司研发,基于Qwen底座模型,通过针对性合成症状数据、蒸馏训练及医学专家标注思维链,依托高质量数据完成微调和强化训练。2025年7月,该模型以64.94分的成绩通过国家妇产科卫生高级职称(正高)笔试考试,成为首成为国内首个达到主任级医师水平的垂直医疗模型
Xiaomi MiMo
Xiaomi MiMo是小米公司自研的AI大模型系列,定位为“定义智能体时代的旗舰基座大模型”。它不仅是单纯的技术产品,更是小米“人车家”全生态战略的核心智能底座。
大模型实验室Lab4AI
大模型实验室Lab4AI是提供高性能GPU场景的实操平台和内容社区,致力于为高校科研人员、AI开发者和学习者提供高性能算力支持与全链条工具服务,打造“从论文到创新,从课程到实践”的闭环生态。平台聚焦科研探索与技能提升两大核心场景,通过集成先进AI能力、云端算力资源和实操环境,助力用户高效完成学术研究
LLaMA-Factory Online
LLaMA-Factory Online是与明星开源项目LLaMA-Factory官方合作精心打造的在线大模型训练与微调服务平台。这个平台专为那些有微调需求,但工程能力不太强的用户群体量身定制,提供开箱即用、低代码、全链路功能覆盖的大模型训练与微调服务。
豆包AI官网
豆包AI(doubao)是字节跳动开发的AI智能助手,能通过文字与用户互动,提供聊天、知识解答、创意内容生成等服务,像回消息、解数学题、写文案都不在话下。它基于先进技术,持续优化以理解用户需求,为大家带来便捷的智能交互体验,是日常生活和工作中可信赖的AI助手。
Audio2Face
Audio2Face是英伟达推出的一款生成式AI面部动画模型,该模型通过深度学习和机器学习算法,实现了从音频输入到面部动画输出的实时转换。近日,英伟达宣布开源了这一模型,不仅提供了核心算法,还附带了软件开发工具包(SDK)和完整的训练框架,为游戏和3D应用领域的智能虚拟角色开发提供了强有力的支持。
F-Lite
F-Lite是一款基于扩散变换器架构的文本到图像生成模型,由Black Forest Labs开发并于2025年最高1024x1024图像,并具备开源特性,适用于正式登陆Hugging Face平台。该模型以10亿参数的轻量化设计,实现了高效、低成本的图像生成能力,支持通过自然语言提示生成高分辨率
SongGeneration
SongGeneration是腾讯AI Lab正式推出并开源的一款音乐生成大模型。它旨在解决音乐生成领域中普遍存在的音质、音乐性和生成速度等三大难题,通过先进的技术架构和算法,实现高质量音乐作品的自动创作。
0
0
欢迎来到AI Top100!我们聚合全球500+款AI智能软件,提供最新资讯、热门课程和活动。我们致力于打造最专业的信息平台,让您轻松了解全球AI领域动态,并为您提供优质服务。
合作伙伴



