
阿里全新一代智能模型Qwen3.7-Max正式接入千问App、PC端和网页端
5月22日,阿里千问官方宣布,全新一代智能模型Qwen3.7-Max正式接入千问App、PC端和网页端。用户只需将千问App更新至6.9.7及以上版本,便可通过应用内的"Qwen3.7-Max"按钮进行切换。
Qwen3.7-Max不仅是一款普通的AI模型,更是一个全能的智能体基座。其设计旨在处理多种复杂任务,无论是编写和调试代码,还是实现办公流程自动化,甚至在长达数百小时的任务中进行自主执行,Qwen3.7-Max都能胜任。在编程领域,Qwen3.7-Max可以处理从前端原型开发到复杂多文件工程的各种任务,极大提高了开发效率。在办公与生产力方面,通过多智能体协作与工作流自动化,Qwen3.7-Max使得日常办公变得更加高效。
最亮眼的是长周期任务表现:曾在一项长达35小时、超过1000次工具调用的实验中展现出稳定的推理和执行能力,这意味着其在复杂任务中也能持续发挥作用。
此外,Qwen3.7-Max不仅在阿里云百炼平台上提供服务,还具备跨框架泛化能力,能够在Claude Code、OpenClaw、Qwen Code等多个框架中稳定运行,为开发者和企业提供了更大的灵活性与选择。
详情查看: https://www.aitop100.cn/infomation/details/33881.html

1.5万亿参数!Grok V9-Medium训练完成,xAI正面硬刚编程AI赛道
5月25日,埃隆·马斯克正式宣布,xAI旗下最新旗舰模型Grok V9-Medium已完成训练阶段。作为一款拥有1.5万亿(1.5T)参数的超大规模基础模型,其规模是目前支撑Grok所有生产线流量的v8-small版本(0.5T参数)的整整三倍。
核心看点有几个。首先是规模跨越:从0.5T直接跃升至1.5T参数,模型在推理深度与复杂任务处理能力上实现了质的飞跃。其次是编程特化:在补充训练阶段,xAI引入了海量Cursor(AI编程工具)的代码数据,旨在显著增强其处理复杂编程任务的能力。目前模型已进入监督微调(SFT)阶段,强化学习(RL)即将启动,预计在2至3周内正式面向公众发布。此外,马斯克透露该模型经过了针对NVIDIA Blackwell架构GPU的深度优化,算力效率将大幅提升。
Grok V9-Medium的发布,最引人瞩目的在于其"编程基因"。马斯克此前曾坦言,现有的v8-small版本在训练数据的质量、全面性及比例平衡上存在明显短板,而V9-Medium则是针对这些痛点进行的系统性重构。
通过引入Cursor的代码逻辑与实战数据,xAI意图让这款新模型在开发者生态中建立绝对的技术优势。Cursor作为当前主流的AI编程辅助工具,其背后的代码调用习惯、工程化思路和bug修复路径代表了顶尖软件工程的实践。
详情查看: https://www.aitop100.cn/grok-v9-medium

中国首个1.58-bit大模型发布!面壁智能+清华用华为昇腾训练成功,8B模型能跑手机
近日,面壁智能联合清华大学及OpenBMB开源社区,正式发布并开源了中国首个基于华为昇腾平台训练的三值(1.58-bit)大模型——BitCPM-CANN。该模型在低比特大模型训练领域取得了重大突破。
BitCPM-CANN的推出,不仅展示了国产算力平台的强大实力,还实现了从量化算子到训练算法的全链路原生开发。该模型分为0.5B、1B、3B和8B四个尺寸,性能表现卓越,相较于同尺寸的全精度家族MiniCPM4进行了逐项对照评测,结果令人振奋。BitCPM-CANN在推理阶段能够释放约6倍的显存红利,这意味着一个8B参数的模型能够轻松运行在当前主流旗舰手机上,为手机产业带来了极大的便利。
面壁智能基于MindSpeed与Megatron-LM搭建了完整的低比特训练底座,涵盖了环境适配、32K长序列支持、并行策略、融合算子等工程体系。
今后,所有面向昇腾的低比特训练工作都可以依托这一套公共基础设施,这不仅降低了开发门槛,也加快了技术的迭代速度。目前BitCPM-CANN的所有模型权重均已开源,用户可以通过HuggingFace和ModelScope平台获取。
详情查看: https://www.aitop100.cn/infomation/details/33879.html

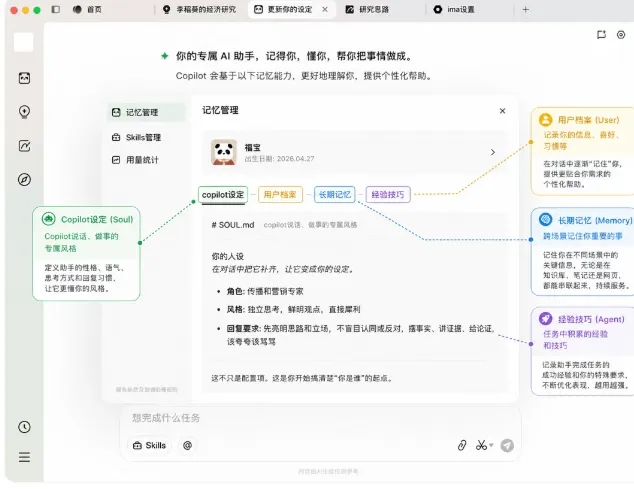
腾讯ima Copilot全面开放!取消排队,还推出知识技能分享平台
人工智能知识管理平台ima于今日宣布,对其备受期待的AI智能体(Agent)产品"Copilot"取消排队机制,实现全面开放。此前,该功能由于拥有记忆、个性化定制等特性,吸引超10万用户排队等候。
ima Copilot被定位为一个"懂你、给你办事的知识Agent"。它不仅拥有持续进化的记忆和全场景感知能力,可无缝调用用户知识库中的内容,还支持用户自行接入外部模型API以及扩展自定义功能(Skill)。官方演示了Copilot如何通过自然语言指令,自动完成"浏览网页、全网调研、结合知识库、生成可视化报告并存储"等一系列复杂任务,大幅提升工作流的自动化程度。
同期ima发布了另一项重要功能更新:知识号支持发布Skill。用户可以将自己成功的、可复用的工作流程(例如自动处理周报任务)封装为"Skill",并发布到"知识广场"的Skills专区进行分享。这标志着ima的平台定位从"知识内容"管理,延伸至"知识能力"的沉淀与流转。用户既可以在广场发现和取用他人分享的高效技能(如首批上线的"微信读书"、"腾讯招聘"等官方Skill),也能将自己的方法论产品化。
此举意味着ima正从传统的知识管理工具,向一个集"知识沉淀、智能调用、能力共享"于一体的"知识+Agent"平台演进。
详情查看: https://www.aitop100.cn/infomation/details/33880.html
DeepSeek V4-Pro API永久降价75%!输入缓存命中仅0.025元/百万tokens,创全球新低
DeepSeek官方宣布,旗下DeepSeek-V4-Pro模型API在2026年5月31日结束限时优惠后将不再恢复原价,而是正式转为永久降价,直接调整为原定价的四分之一。
此前,该模型于4月26日推出了全系API价格调整,将输入缓存命中价格降至首发价的十分之一,并叠加了限时2.5折的V4-Pro优惠活动。本次策略调整意味着这一极具竞争力的价格将成为常态。
调整后,DeepSeek-V4-Pro的API定价创下全球大模型价格新低。具体而言,每百万tokens的输入(缓存命中)价格仅为0.025元,输入(缓存未命中)价格为3元,输出价格则为6元。这一量级的数据降幅,不仅展示了DeepSeek在模型架构优化与算力效率上的技术底座实力,更通过极致的成本控制颠覆了现有的商业化定价体系。
当前,大模型行业正加速从"技术涌现"走向"商业落地",企业级客户对算力成本与调用效率的敏感度日益提升。DeepSeek将短期促销转化为永久性的大幅降价,预计将进一步降低开发者与企业构建AI应用的门槛,催生更多高频次、大吞吐量的场景化落地。
工具地址:DeepSeek官网

字节跳动发布MMProLong:长文档训练问答对效率远超OCR转录,256K上下文稳如狗
2026年5月24日,字节跳动Seed团队联合香港科技大学发布了一项针对多模态大语言模型(LMM)长文档训练的最新研究成果。研究人员基于阿里巴巴开源的Qwen2.5-VL构建了名为MMProLong的新模型,并在长文档处理效率上取得突破性进展。
这项研究的核心发现直击当前LMM训练的痛点:在多模态长文档训练中,针对特定目标进行问答对(QA)训练的效果显著优于传统的字符识别(OCR)转录。实验表明,纯文本转录作为训练任务非但无法提升模型在长上下文中的定位能力,反而会导致性能下降;而通过独立模型(如字节跳动Seed2.0)生成的长上下文问答对进行训练,则能引导模型在冗长干扰信息中精准检索目标段落。
基于这一优化策略,MMProLong在仅128,000个Token的有限训练预算下,展现出极强的长文本稳定性,在输入长度达到256,000乃至512,000个Token时依然没有出现性能崩溃,并在MMLongBench和MM-NIAH(大海捞针)基准测试中大幅超越InternVL3-38B和Gemma3-27B等体量更大的开源模型。此外,MMProLong的多模态能力还成功迁移至未经专门训练的长视频理解任务中,并在Qwen3-VL-8B模型上同样验证了该策略的有效性。
此项研究为当前大模型行业提供了一条不同于DeepSeek(通过视觉信息高度压缩与重新排序升级架构)的演进路线,证明了通过优化训练数据结构而非改动底层架构,同样能实现长上下文能力的跨越式提升。

微软发布Fara1.5系列智能体模型:任务成功率72%超越OpenAI,浏览器场景最强AI来了
微软研究院AI Frontiers实验室近日发布了全新的Fara1.5系列智能体模型。这一系列专为浏览器场景设计,旨在提升计算机使用的智能化水平。Fara1.5系列涵盖了三个不同参数规模的版本,分别是4B、9B和27B。
这款智能体模型与MagneticLite沙盒浏览器界面配合使用,能够直接读取浏览器的截图,并通过模拟鼠标和键盘操作,自动完成各种网页任务。Fara1.5的工作流程基于"观察—思考—行动"的循环,每一步都结合历史对话和最近的三张浏览器截图,以此生成推理内容和后续动作。
在性能方面,Fara1.5-27B在Online-Mind2Web基准测试中取得了72%的任务成功率,显著高于OpenAI的Operator(58.3%)和Gemini2.5 Computer Use(57.3%)等竞品。而即使是Fara1.5-9B版本,其成功率也达到了63.4%。
Fara1.5的训练采用了约200万条样本进行微调,其中60%来自网页轨迹,12.8%来自合成环境,12.5%与用户交互有关,8.8%为事实锚定,4.9%则来源于视觉问答。
为确保用户的安全与隐私,Fara1.5在以下三种情况下会主动停止操作并询问用户:缺少个人信息、任务描述不清晰以及即将执行未经批准的不可逆操作。

AITOP100-AI资讯频道将持续关注AI行业新闻资讯消息,带来最新AI内容讯息。
想了解AITOP100平台其它版块的内容,请点击下方超链接查看
AI创作大赛 | AI活动 | AI工具集 | AI资讯专区 | AI小说
AITOP100平台官方交流社群二维码:











