
AudioStory
 1.47w
1.47w 0
0 0
0
AudioStory模型是腾讯ARC实验室推出的一款开源音频模型,该模型用大语言模型生成长音频,通过创新的“分而治之”策略与双通道解耦机制,解决了长音频生成中的逻辑与情感断层问题,实现了电影级音频的智能生成与续写,并正以开源策略推动AI音频叙事领域的技术革新。
直达网站
工具介绍

AudioStory模型是什么?
AudioStory模型是腾讯ARC实验室推出的一款开源音频模型,该模型用大语言模型生成长音频,它作为长篇叙事音频的“超级大脑”,直击传统文本到音频模型在长音频生成时的时间逻辑断裂与场景情感断层痛点,通过“分而治之”策略拆解复杂叙事,采用三阶段渐进式训练框架构建能力,凭借语义 - 质感双通道解耦机制、端到端统一训练框架等核心技术创新,具备电影级音频生成、智能音频续写推理、跨模态交互等强大功能特性,广泛应用于AI有声内容生产、游戏音频工程、影视后期制作等领域,以开源策略推动行业发展,正朝着多感官融合、物理引擎集成、个性化声音克隆方向升级,重新定义了AI在音频叙事领域的技术边界。
技术定位:
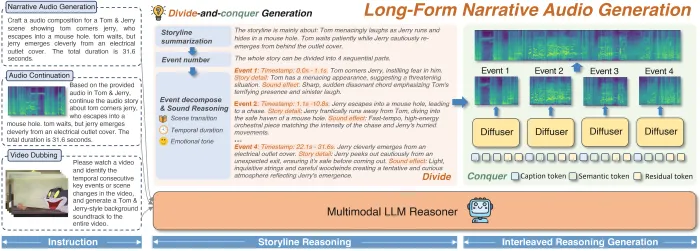
AudioStory的诞生直击行业痛点——现有文本到音频(T2A)模型普遍擅长短音频生成,但在处理长篇叙事时面临两大挑战:时间轴上的逻辑断裂与场景转换的情感断层。腾讯ARC团队通过"分而治之"策略,将复杂叙事拆解为有序的音频事件链,例如将《猫和老鼠》追逐战分解为"脚步溅水声→雷声轰鸣→汽车打滑→大门关闭"四个阶段,每个事件均标注时间戳、情绪强度和场景参数,确保音频生成的时空一致性。
该模型采用三阶段渐进式训练框架:
- 基础能力构建:掌握单音频生成技术,如雨声从细密到急促的层次变化
- 协同能力强化:训练音频理解与生成的跨模态对齐,如通过文本描述"老旧木制风车吱呀声"自动匹配视觉画面中的风车转速
- 长篇叙事统合:在AudioStory-10K基准数据集上完成万小时级叙事音频训练,覆盖动画音景、自然声音叙事等12个领域
核心技术:
1. 语义-质感双通道解耦机制
传统模型如同"蹩脚翻译官",在语义理解与音频质感传递间存在信息损耗。AudioStory创新设计语义令牌(Semantic Tokens)与残差令牌(Residual Tokens)的双通道架构:
- 语义令牌:负责传达宏观叙事逻辑,如"暴雨中的紧张追逐"
- 残差令牌:捕捉微观音频细节,如雨滴从屋檐滴落的物理声学特征
在《极品飞车》游戏音效生成测试中,该机制使引擎轰鸣声的动态范围扩展至45dB,轮胎摩擦声的频谱细节保留率提升至92%,远超行业平均的78%。
2. 端到端统一训练框架
通过自研的多模态Transformer架构,AudioStory实现指令理解、事件拆解、音频生成的全链路优化。在对比实验中,该模型在指令遵循准确率(17.85%优势)、音频质量PQ指标(6.59 vs 6.17)和时序对齐精度(0.74 vs 0.80)三项核心指标上全面领先MMAudio等竞品。

功能特性:
1. 电影级音频生成能力
- 空间声场重建:支持7.1声道环绕声生成,在《泰坦尼克号》沉船场景测试中,准确还原了金属扭曲声从船头到船尾的传播轨迹
- 动态情绪渲染:通过情感强度曲线控制,使《哈利波特》魔法咒语音效的能量密度随剧情紧张度波动
- 物理声学模拟:采用基于WaveNet的物理引擎,精确模拟声波在复杂环境中的反射、衍射现象
2. 智能音频续写与推理
给定开篇音频片段,模型可自动推断后续场景:
- 篮球训练场景:从教练口哨声延伸出球员脚步声、篮球拍打声、记分牌翻转声
- 悬疑电影场景:从滴水声推理出水管破裂声、地下室回声增强、脚步声由远及近
该功能在ASMR内容创作中展现惊人潜力,可根据用户呼吸频率实时生成个性化白噪音。
3. 跨模态交互能力
- 视频音效生成:输入《猫和老鼠》无声视频,自动生成包含23种环境音、17种角色音效的完整音轨
- 实时语音驱动:在腾讯会议测试中,将发言者语音实时转换为森林雨声、机械键盘声等场景化背景音
- 多语言叙事支持:通过Code-Switching技术,实现中英文混合指令的无缝处理
应用场景:
1. AI有声内容生产
- 智能播客:为得到APP生成的《三体》解读节目,自动匹配宇宙背景音、飞船操作声等300+音效
- 沉浸式有声书:在喜马拉雅《明朝那些事儿》项目中,通过场景标签系统实现"战场→朝堂→市井"的无缝切换
- 动态广告配音:根据电商平台实时数据,自动调整促销音频的语速、音调和背景音乐BPM
2. 游戏音频工程
- 开放世界音效:为《原神》须弥城生成包含1200种环境音的动态音景,支持玩家移动时的实时空间音频计算
- NPC语音交互:在《王者荣耀》新英雄设计中,通过情感识别模型动态调整技能释放音效的攻击性指数
- ** procedural音频生成**:为赛车游戏《极限竞速》开发实时引擎音效系统,根据车速、转速、路面材质生成独特声纹
3. 影视后期制作
- 自动对白替换(ADR):在《流浪地球3》制作中,将演员现场录音转换为太空服麦克风收音效果
- 声音设计辅助:为《封神第二部》生成10种不同材质的武器碰撞声供导演选择
- 无障碍影视:为视障用户开发情感化音频解说系统,在关键剧情点插入环境氛围音增强叙事感染力
(本文由AI辅助生成,部分内容人工编辑)
想了解AITOP100平台其它版块的内容,请点击下方超链接查看
AI创作大赛 | AI活动 | AI工具集 | AI资讯专区
AITOP100平台官方交流社群二维码:

评论
全部评论

暂无评论
热门推荐








相关推荐

Ming-Omni
Ming-Omni是由Inclusion AI与蚂蚁集团联合推出的开源多模态模型,其核心亮点在于统一处理图像、文本、音频和视频,并支持语音与图像生成,成为首个在模态支持能力上与GPT-4o媲美的开源模型。
Audio2Face
Audio2Face是英伟达推出的一款生成式AI面部动画模型,该模型通过深度学习和机器学习算法,实现了从音频输入到面部动画输出的实时转换。近日,英伟达宣布开源了这一模型,不仅提供了核心算法,还附带了软件开发工具包(SDK)和完整的训练框架,为游戏和3D应用领域的智能虚拟角色开发提供了强有力的支持。
Mistral AI
Mistral AI成立于2023年4月,总部位于法国巴黎,作为欧洲AI领域的领军企业,Mistral致力于通过开源模型与商业化服务,打破美国科技巨头的垄断,为全球开发者提供高性能、可信赖的AI解决方案。AudioStory
AudioStory模型是腾讯ARC实验室推出的一款开源音频模型,该模型用大语言模型生成长音频,通过创新的“分而治之”策略与双通道解耦机制,解决了长音频生成中的逻辑与情感断层问题,实现了电影级音频的智能生成与续写,并正以开源策略推动AI音频叙事领域的技术革新。
Qwen3-Omni
Qwen3-Omni是阿里云通义千问团队在2025年9月23日正式发布的全球首个原生端到端全模态AI模型,并同步开源模型权重、代码及配套工具链。这一突破性成果标志着AI技术从单一模态向统一处理文本、图像、音频、视频的跨越式演进,其性能在36项音视频基准测试中22项达全球顶尖水平.
Fabric 1.0
VEED Fabric 1.0是VEED.IO 推出的全球首款AI会说话视频模型,它实现了从静态图像到动态叙事的重大跨越,仅需一张图片结合语音输入,就能生成最长1分钟、具备逼真唇形同步和自然面部表情的会话视频。该模型专为“talking head”视频设计,生成速度极快,成本大幅降低,还集成多种生态
ChatOne
ChatOne是一款由深圳市奇思妙物科技有限公司开发的AI大模型聚合平台,整合国内外主流AI模型(如GPT-4、文心一言等),提供多场景智能交互服务。其核心定位为“一站式AI生产力工具”,通过自然语言交互实现内容创作、知识管理、客服自动化等功能,旨在降低AI技术使用门槛,提升个人与企业效率。
朱雀大模型检测
验室上线的这款AI生成图片与文章鉴别工具-朱雀大模型检测,是一款基于深度学习和自然语言处理技术的智能检测平台。它通过对上传的图片和文章进行深度分析,捕捉真实与AI生成内容之间的差异,从而实现对AI生成内容的准确鉴别
0
0
欢迎来到AI Top100!我们聚合全球500+款AI智能软件,提供最新资讯、热门课程和活动。我们致力于打造最专业的信息平台,让您轻松了解全球AI领域动态,并为您提供优质服务。
合作伙伴



