
F-Lite
 9946
9946 0
0 0
0
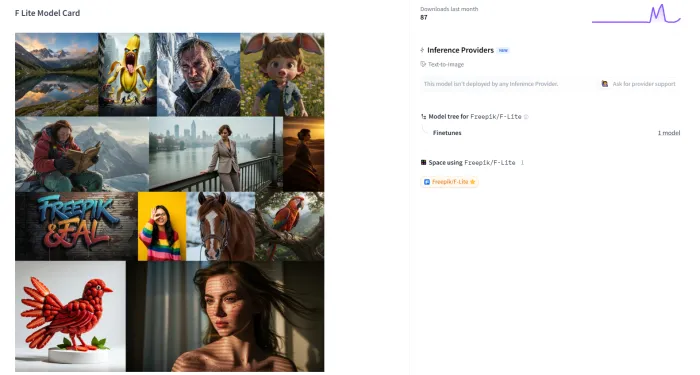
F-Lite是一款基于扩散变换器架构的文本到图像生成模型,由Black Forest Labs开发并于2025年最高1024x1024图像,并具备开源特性,适用于正式登陆Hugging Face平台。该模型以10亿参数的轻量化设计,实现了高效、低成本的图像生成能力,支持通过自然语言提示生成高分辨率
直达网站
工具介绍
F-Lite是什么
F-Lite是一款基于扩散变换器(Diffusion Transformer)架构的文本到图像生成模型,由Black Forest Labs开发并于2025年正式登陆Hugging Face平台。该模型以10亿参数的轻量化设计,实现了高效、低成本的图像生成能力,支持通过自然语言提示生成高分辨率(最高1024x1024)图像,并具备开源特性,适用于消费级硬件部署。

核心优势
- 轻量化设计F-Lite通过优化模型结构,将参数规模压缩至10亿,相比FLUX.1的120亿参数模型,推理效率显著提升,可在RTX3060等中端GPU上流畅运行,显存需求仅需12GB VRAM。
- 高效生成能力采用时间步精炼技术,默认采样步数减少至28步,生成单张高质量图像仅需数秒,推理速度比Stable Diffusion v1.5快约20%。
- 开源与定制化模型检查点与推理代码已通过Hugging Face公开,支持PyTorch与FLAX框架,开发者可自由定制控制模式或微调模型,推动社区创新。
- 量化优化支持int4与bfloat16量化,进一步降低显存占用,适配消费级设备,显著提升模型的可访问性。
主要功能
- 文本到图像生成用户可通过自然语言提示(如“雪山下的未来城市,赛博朋克风格”)生成高分辨率图像,支持复杂场景与风格化需求。
- 控制模式增强兼容深度控制(Depth Control)与Canny边缘控制,通过通道拼接实现类似ControlNet的效果,增强结构控制能力。
- 多模态扩展潜力支持Model Context Protocol(MCP),未来可与Qwen-Agent等框架集成,扩展多模态任务能力。
需求人群
- 开发者与研究者需要轻量化模型进行快速原型验证或学术研究的开发者,可利用F-Lite的开源特性进行二次开发。
- 中小型创作者与工作室独立艺术家、游戏开发者、影视团队等可通过F-Lite降低硬件成本,提升内容生产效率。
- 教育与科普机构教育机构可利用F-Lite生成教学插图或科学场景,增强课堂互动与研究展示。
应用场景
- 数字艺术与NFT快速生成风格化图像,适配OpenSea等平台,助力艺术家提升创作效率。
- 游戏与影视生成概念场景或角色设计,缩短前期美术周期,适合独立开发者与工作室。
- 电商与广告创建产品展示图像,提升Shopify或Instagram营销吸引力。
- 个性化创作为社交媒体生成定制化内容,如节日贺卡或表情包,满足用户分享需求。
使用教程
1.环境准备推荐硬件:CUDA兼容GPU(12GB+ VRAM)安装依赖:运行pip install diffusers==0.10.2 transformers scipy ftfy accelerate
2.模型加载代码
3.生成图像代码

4.高级定制调整参数:通过guidance_scale优化生成质量启用控制模式:结合Canny边缘控制增强结构细节
未来发展
- 技术升级Black Forest Labs计划在下一版本中增强高分辨率生成能力,优化VAE解码器以提升4K分辨率下的细节表现。
- 多模态扩展探索视频生成支持与多语言提示兼容性,推动F-Lite从静态图像生成向动态内容生成扩展。
- 生态整合可能与NVIDIA NIM Operator2.0的微服务框架整合,构建企业级生成工作流;或与Gen-4References的图像混合技术结合,实现动态内容生成。
- 社区化服务长期来看,F-Lite可能推出“生成模板市场”,提供共享提示与模型微调服务,构建类似Hugging Face的生态模式。
结语
F-Lite的推出标志着文本到图像生成技术向轻量化与普及化的迈进。其10亿参数架构与开源支持不仅挑战了SDXL与DALL-E3的高资源需求,还为中小型开发者提供了低门槛创作工具。无论是个人创作者还是企业用户,均可通过F-Lite探索AI图像生成的无限可能。
评论
全部评论

暂无评论
热门推荐








相关推荐

Hermes 4
Hermes 4是Nous Research于2025年8月发布的开源混合推理大型语言模型(LLM)系列,其核心突破在于将结构化多步推理与指令跟随能力深度融合,在数学、编程、逻辑推理等任务中达到行业领先水平,同时通过“无内容限制”设计重新定义了开源AI的边界。
千问云
千问云(Qwen Cloud)是阿里云于2026年5月20日在阿里云峰会上正式发布的全新AI产品官网,定位为"为Agent而生的全栈智能基础设施"。平台聚合了150余个模型系列、480余款主流模型API,覆盖Qwen、GLM、Kimi、DeepSeek、Wan、HappyHorse等国内外主流大模型
子曰-o1
“子曰-o1”是网易有道基于多年教育数据和AI技术积累,推出的一款轻量级推理模型。它采用14B的小参数设计,能够在普通消费级显卡上高效部署,专为教育场景设计。该模型利用思维链技术,通过自我对话和纠错机制,在解题时输出详细的思考过程,帮助学生理解解题逻辑,提升学习效果。
Quasar Alpha
Quasar Alpha是一款近期神秘亮相的全新AI模型,由一家未具名的模型实验室推出,被称为其首款“隐秘”模型,是即将发布的长上下文基础模型的预发布版本。它凭借超长的上下文处理能力、优化的编码能力,以及免费开放策略,迅速成为业界热议焦点,为AI技术发展增添了新期待。
智谱清言
智谱清言是由北京智谱华章科技有限公司推出的一款生成式AI助手,也可被称为ChatGLM。它集文本生成、图片生成、音视频生成等多种功能于一体的智能创作系统,基于深度学习技术,可以实现文章自动生成、智能改写、关键词提取等功能。
天工AI大模型
昆仑万维天工AI大模型是昆仑万维集团自主研发的一系列大型语言模型(LLMs),旨在通过先进的自然语言处理和深度学习技术,为用户提供高效、智能的服务和体验。该系列模型不仅具备强大的语言理解和生成能力,还广泛应用于教育、企业客服、新闻媒体、创意产业、医疗、法律咨询、金融服务等多个行业。
Sana
Sana是英伟达开源的一款先进图像生成模型,它采用了深度压缩自编码器(DC-AE)和线性扩散变换器(DiT)等创新技术,能够在保持高质量图像生成的同时,实现极快的生成速度。这款模型支持生成高达4096×4096分辨率的图像,并且在16GB显卡上即可流畅运行,满足了广大用户对于高效图像生成的需求
讯飞星辰Maas平台
讯飞星辰作为科大讯飞倾力打造的AI大模型定制训练平台,致力于为用户打造独一无二的专属大模型。该平台汇聚了超过20个在行业内广受认可的优质模型,诸如星火大模型、Llama3等,均在其列。更为便捷的是,讯飞星辰支持零代码微调功能,极大地降低了大模型精调的复杂性和门槛。
0
0
欢迎来到AI Top100!我们聚合全球500+款AI智能软件,提供最新资讯、热门课程和活动。我们致力于打造最专业的信息平台,让您轻松了解全球AI领域动态,并为您提供优质服务。
合作伙伴



