
最近的大模型圈,有一个信号很值得关注:智谱宣布 GLM-5.2 面向 GLM Coding Plan 全量用户开放,并明确 API 上线与 MIT 协议开源节奏。
这件事表面上是一次模型更新,实际上更像是一场开发者生态的重新下注。
当行业还在比较参数、榜单和单点能力时,GLM-5.2 把几个更落地的问题摆到了台前:模型能不能处理真实工程里的长上下文?企业能不能更可控地部署和二次开发?开发者能不能把先进模型稳定嵌入自己的工作流?

01 这次不是简单“发新模型”
根据公开报道,GLM-5.2 已面向 GLM Coding Plan 全量用户开放,覆盖 Lite、Pro、Max 与团队版。智谱同时提到,GLM-5.2 API 将随后上线,模型也将按 MIT 协议开源。
这里有一个关键区分:“全量开放”解决的是可用性,“正式开源”解决的是可改造性。
前者意味着更多开发者可以直接在产品里体验模型能力;后者则意味着模型有机会进入企业私有化部署、二次开发、插件生态和行业解决方案。
如果说过去大模型竞争的核心是“谁的模型更强”,那现在更关键的问题正在变成:谁能让模型能力更稳定、更开放、更可控地进入真实生产环境。
02 1M上下文,真正瞄准的是工程复杂度
GLM-5.2 的一个核心卖点,是 1M 级别长上下文。
对普通用户来说,长上下文可能只是“能塞更多文字”。但对 AI 编程和智能体来说,它解决的是完全不同层级的问题:
- 不只是看一段代码,而是理解一个仓库;
- 不只是回答一个问题,而是跟踪需求、接口、配置、日志和测试;
- 不只是生成一个片段,而是完成多步骤规划、执行与验证。
这也是为什么 GLM-5.2 会被放在 Coding Plan 里重点开放。AI 编程正在从“代码补全工具”,逐渐演变成“工程协作智能体”。

在真实开发场景中,模型经常不是因为不会写代码而失败,而是因为看不全上下文、找不到关键文件、忽略历史约束,或者在多轮执行中丢失目标。
因此,长上下文的价值不只在长度本身,而在于它能否支撑更长链路的工程任务。
03 MIT开源路线,押注的是生态复用
如果 GLM-5.2 按公开信息所述采用 MIT 协议开源,这会释放一个很强的产业信号:智谱希望把模型能力变成更容易被复用的基础设施。
MIT 协议相对宽松,对商业使用、二次开发和私有化部署更加友好。对企业客户来说,这降低了采用开源模型时的心理门槛;对开发者来说,也意味着可以围绕模型做更多工具链、插件和 Agent 工作流。
但也要看到,开源并不自动等于好用。
真正决定落地速度的,仍然包括推理成本、部署工程、工具链适配、安全治理、模型更新频率,以及社区能否持续沉淀高质量实践。
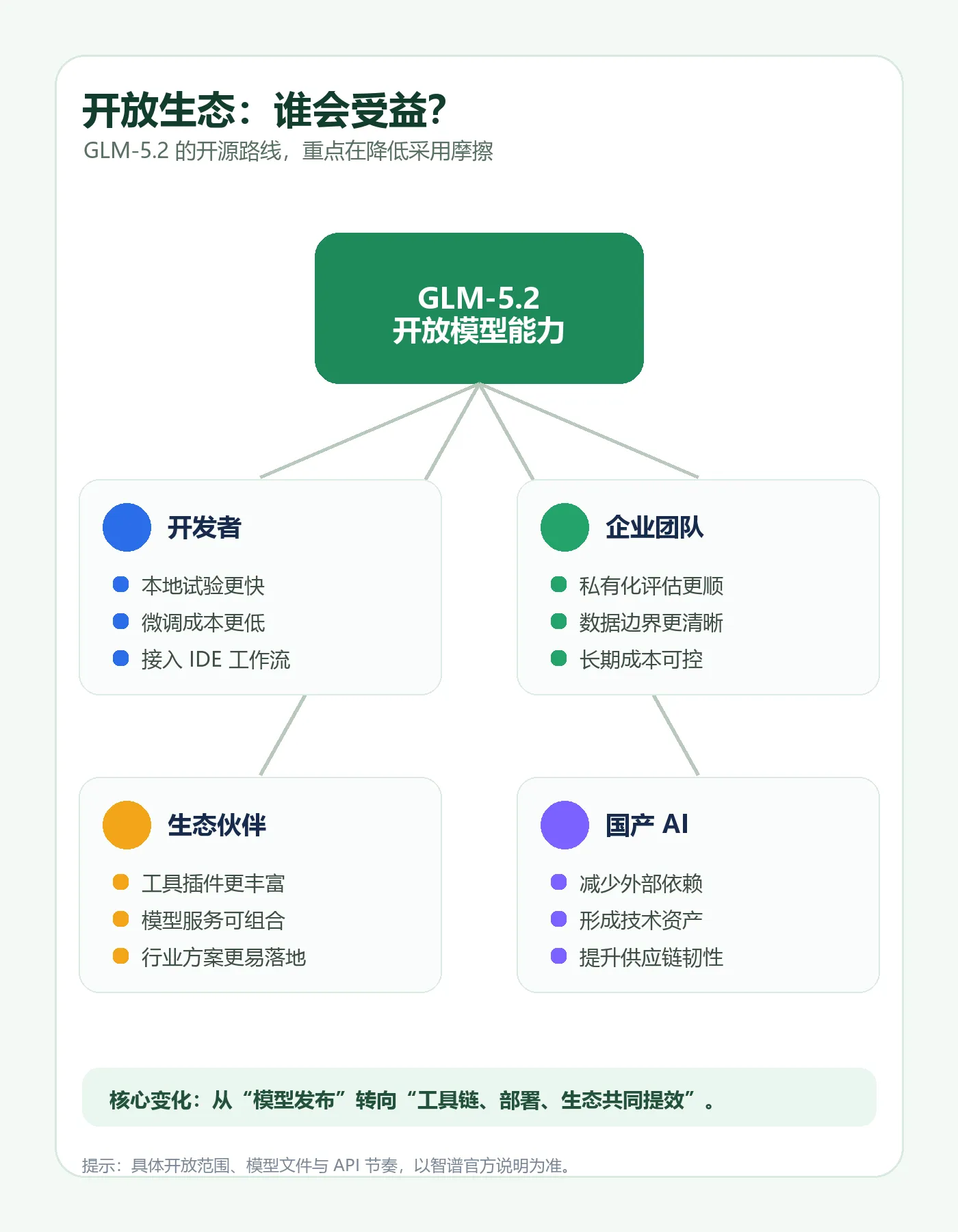
换句话说,GLM-5.2 的看点不只是“开放了一个模型”,而是智谱能否围绕它搭建起一套可持续的开发者生态。
04 国产大模型的“确定性价值”正在上升
这次 GLM-5.2 的开放节奏,也发生在一个特殊背景下:海外前沿模型访问与供应的不确定性正在上升。
对很多企业和开发者来说,先进能力固然重要,但“可持续获得、可控部署、可审计使用”同样重要。
当模型能力进入办公、研发、客服、金融、政企等严肃场景,企业不会只看榜单分数,还会问几个现实问题:
- 这个模型能否长期稳定使用?
- 数据和部署边界是否可控?
- 成本是否可预测?
- 出问题时是否有本地支持与工程响应?
- 能不能沉淀为自己的技术资产?
这正是国产开源模型的机会。
它不一定要在每一个单项指标上都“碾压”闭源模型,但只要能在开放、可控、可部署、可二次开发上形成确定性,就会获得越来越多企业的认真评估。
05 结语:从模型发布,到生态战争
GLM-5.2 的意义,不应只被理解为又一个新模型发布。
更准确地说,它代表着国产大模型竞争正在从“能力展示”进入“生态建设”:谁能把模型做成开发者愿意用、企业敢于部署、平台能够商业化的基础设施,谁就更可能在下一阶段占据主动。
1M 上下文是能力入口,MIT 开源是生态入口,Coding Plan 全量开放则是产品入口。
这三件事合在一起,才是 GLM-5.2 真正值得关注的地方。
当然,最终效果还要看 API、开源权重、许可证文件、部署文档和真实开发者反馈的落地情况。对行业而言,最值得期待的不是一句“开源”,而是一个足够开放、足够稳定、足够可复用的 AI 工程底座。

")







