
过去评价 AI 编码智能体,行业最常用的指标是:它最后有没有把 GitHub issue 修好。
这个指标当然重要,但它也有一个问题:如果一个智能体没有修好,我们很难知道它到底卡在哪里。是没理解需求?是没找到相关文件?是定位不到具体代码行?还是改对了地方却写错了补丁?
SWE-Explore 的发布,正是为了解决这个盲区。
公开资料显示,上海交通大学领衔的国际科研团队推出 SWE-Explore 基准,用更细粒度的方式评估 AI 编码智能体在真实仓库中的探索与代码定位能力。它不只看“最终修复成功率”,而是把仓库搜索、文件级定位、行级定位等关键步骤拆出来观察。
换句话说,它揭露的是 AI 编码工具最容易被总分掩盖的短板:不是不会写代码,而是经常没找准该改哪里。

01 为什么“定位”比想象中更重要?
真实软件工程任务很少是孤立题目。
一个 issue 背后,往往牵涉多个文件、历史逻辑、调用链、测试用例和隐含约束。工程师解决问题时,第一步不是写补丁,而是先找到问题在哪里。
对 AI 编码智能体也是一样。
如果它没有找到关键文件,再强的生成能力也可能写出无关代码;如果它定位不到具体行,补丁就容易偏离真正原因;如果它在仓库里反复搜索却没有有效收敛,最终就会浪费大量 Token 和时间。
因此,代码定位能力决定了 AI 编码智能体能不能真正进入复杂工程场景。

02 SWE-Explore 解决了什么评测问题?
传统 SWE-bench 类评测更关注最终任务结果:模型是否解决了真实 GitHub issue。
SWE-Explore 的价值在于,把“最终是否修好”之前的探索过程拆开评估。它让我们能看到智能体在代码仓库中到底经历了什么:
- 是否找到了与 issue 相关的文件;
- 是否能进一步定位到关键函数或代码片段;
- 是否能以行级精度找到真正需要修改的位置;
- 是否在探索过程中出现路径偏移、无效搜索或过度尝试。
这会让 AI 编码能力评估从“结果黑箱”变成“过程显微镜”。

03 它揭示了 AI 编码的一个现实问题
很多模型在写代码时看起来越来越强,但在真实仓库里,难点并不只是生成语法正确的代码。
真正难的是:在几十万行代码中,理解问题、定位上下文、判断依赖关系,再做最小且正确的修改。
SWE-Explore 所强调的“行级定位”,就是这个能力的核心表现。
如果 AI 只能大致找到文件,却找不到具体行,它就像一个知道病人在医院里,却找不到病灶的医生。最终修复成功率自然会受影响。
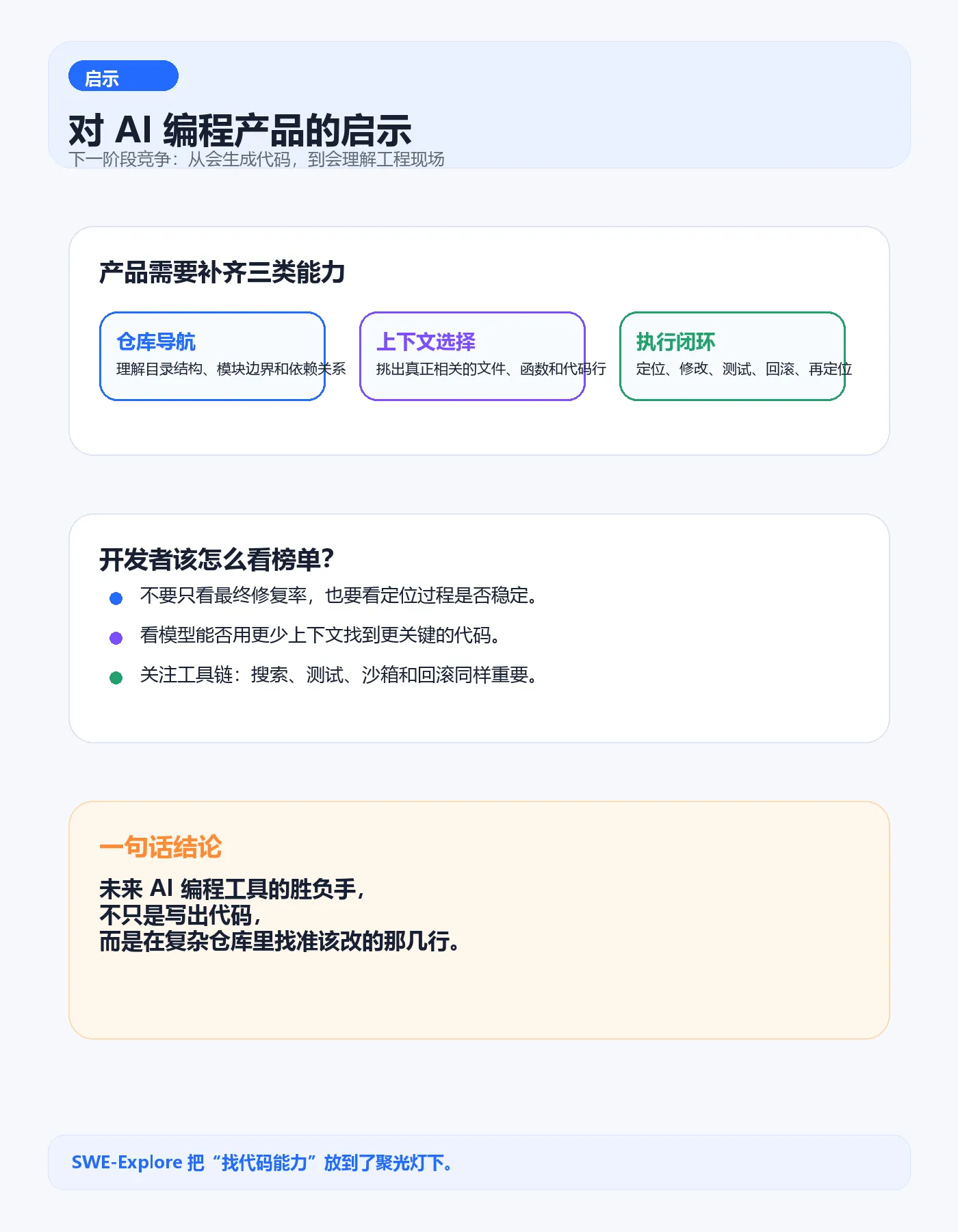
04 对 AI 编程产品意味着什么?
SWE-Explore 的意义,不只是多了一个排行榜。
它会倒逼 AI 编程产品从“会生成代码”转向“会理解工程现场”。未来真正好用的编码智能体,至少要补齐三类能力:
第一,更强的仓库导航能力。能理解目录结构、模块边界和调用关系。
第二,更精确的上下文选择能力。知道哪些文件、函数和代码行值得放进上下文。
第三,更稳的执行闭环。定位、修改、测试、回滚和再定位要形成可控流程。
这也是 AI 编码从 Demo 走向生产级工具必须跨过的一关。
05 一句话结论
SWE-Explore 发布的价值,在于把 AI 编码智能体的“找代码能力”单独摆上台面。
当行业不再只看最终修复率,而是开始追问“它有没有找到关键文件、关键函数和关键代码行”,AI 编程工具的竞争也会更接近真实工程现场。
未来,能写代码只是入场券;能在复杂仓库里精准定位,才是 AI 编码智能体真正的分水岭。

")







