
2025年11月25日,一则重磅消息在AI领域引起了广泛关注:AMD携手IBM与AI初创公司Zyphra,共同发布了全球首个全程基于AMD硬件训练的MoE基础模型——ZAYA1。这一成果不仅展示了AMD在AI硬件领域的强大实力,也为大模型的发展开辟了新的方向。

训练规模:强大集群与海量数据铸就坚实基础
ZAYA1的训练规模堪称庞大。其训练集群采用了IBM Cloud的128个节点,每个节点配备8张AMD Instinct MI300X显卡,总共拥有1024张显卡。通过InfinityFabric高速互联技术和ROCm计算平台,整个集群的峰值算力高达750PFLOPs。如此强大的计算能力,为ZAYA1的训练提供了坚实的硬件保障。
在数据方面,ZAYA1预训练使用了14T tokens的海量数据。这些数据并非随机选取,而是采用了课程学习的方式,从通用网页数据逐步过渡到数学、代码、推理等特定领域的数据。这种有针对性的数据训练方式,使得ZAYA1在特定领域能够具备更强的能力。而且,这还只是预训练版本,后训练版本的数据和性能提升值得期待,后续版本也将另行发布。
架构创新:两大技术突破提升模型性能
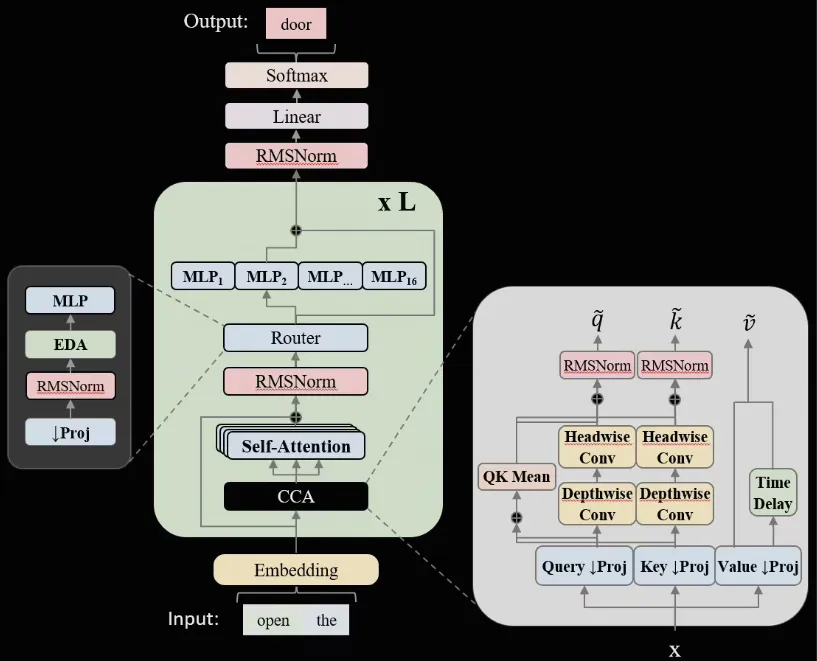
ZAYA1在架构上进行了大胆创新,引入了两项关键技术:CCA注意力和线性路由 MoE。
CCA注意力:这是一种将卷积与压缩嵌入注意力头相结合的技术。传统的注意力机制在处理长上下文时,往往会占用大量的显存,导致训练效率低下。而CCA注意力通过引入卷积操作,减少了显存占用,显存占用下降了32%。同时,它还提高了长上下文的吞吐量,长上下文吞吐提升了18%,使得模型能够更高效地处理复杂的文本信息。
线性路由 MoE:MoE(Mixture of Experts)是一种将多个专家模型组合在一起的技术,能够提高模型的稀疏性和效率。ZAYA1采用的线性路由 MoE 技术,进一步细化了专家粒度,并引入了负载均衡正则化。这使得 Top-2 路由精度提升了 2.3pp,即使在稀疏度达到 70%时,仍能保持高利用率,有效提高了模型的训练效率和性能。
基准成绩:综合性能持平,STEM领域潜力巨大
在基准测试中,ZAYA1展现出了强大的实力。ZAYA1-Base(非指令版)在 MMLU-Redux、GSM-8K、MATH、ScienceQA 等多个基准测试中,与 Qwen3-Base 打平,综合性能表现相当出色。特别是在数学和科学推理领域,ZAYA1 展现出了巨大的潜力。在 CMATH 和 OCW-Math 测试中,ZAYA1 显著超越了 Qwen3-Base,这表明 ZAYA1 在数学和 STEM(科学、技术、工程和数学)领域具有独特的优势,即使未经指令微调,其数学/STEM 推理能力也能逼近 Qwen3 专业版。
Zyphra 透露,指令与 RLHF(基于人类反馈的强化学习)版本将于 2026 年第一季度推出,届时还将开放 API 与权重下载。这意味着更多的开发者和企业将能够使用 ZAYA1 进行二次开发和应用,进一步推动 AI 技术的发展。
未来发展:AMD推动“纯AMD”集群方案普及
AMD表示,此次与 IBM 和 Zyphra 的合作,成功验证了 MI300X + ROCm 在大规模 MoE 训练中的可行性。未来,AMD 将与更多云厂商合作,复制“纯 AMD”集群方案,目标是在 2026 年训练超过 100B 参数的 MoE 模型时,实现与 NVIDIA 方案的总拥有成本(TCO)持平。这一目标的实现,将进一步打破 NVIDIA 在 AI 硬件领域的垄断地位,为 AI 行业的发展带来更多的选择和可能性。
ZAYA1的发布是 AI 领域的一个重要里程碑,它不仅展示了 AMD 在 AI 硬件和软件方面的强大实力,也为大模型的发展提供了新的思路和方向。随着后续版本的推出和“纯 AMD”集群方案的普及,我们有理由相信,AI技术将迎来更加广阔的发展前景。
想了解AITOP100平台其它版块的内容,请点击下方超链接查看
AI创作大赛 | AI活动 | AI工具集 | AI资讯专区
AITOP100平台官方交流社群二维码:










