

2025-08-06 17:36:28
每天一个智能体:第2天-历史故事一键出片!

需求分析
这种题材的作品以悬念开场,身份代入,矛盾升级,破局细节,最后紧扣主题收尾。让人欲罢不能。所以作品的完播率还是很高的。如果自己用deepSeek 写文案,即梦作图,然后导入剪映里剪辑,光剪辑的特效,关键帧等都要挠秃头皮,太难了。用coze工作流来制作效率就高太多了。
要拆解工作流我们需要分为两大步骤:
1.梳理视频构成: 这一步是肉眼感知工作流的构成,看一下视频的总体构成有哪些要素。这个视频中包含了图片、文案、背景音乐、开场音乐、旁白音频、关键帧等。
2.捋顺工作流实现思路: 这一步需要理顺基于Coze实现工作流需要哪些步骤。
下面给出用户输入、工作流的实现步骤。
用户输入:
历史故事主题
工作流步骤:
- 定义用户输入
- 基于大模型根据用户输入的历史故事主题生成文案
- 根据故事信息生成故事主角开场绘画提示词
- 生成主角首图并抠图
- 根据故事信息生成分镜文案提示词
- 根据分镜字幕生成图片提示词
- 批量生成图片和字幕的语音
- 设置图片、音频、音乐的时间线
- 将这些素材添加到剪映草稿
- 设置标题、字幕,关键帧的时间线,并添加到剪映草稿
- 返回视频地址
工作流拆解
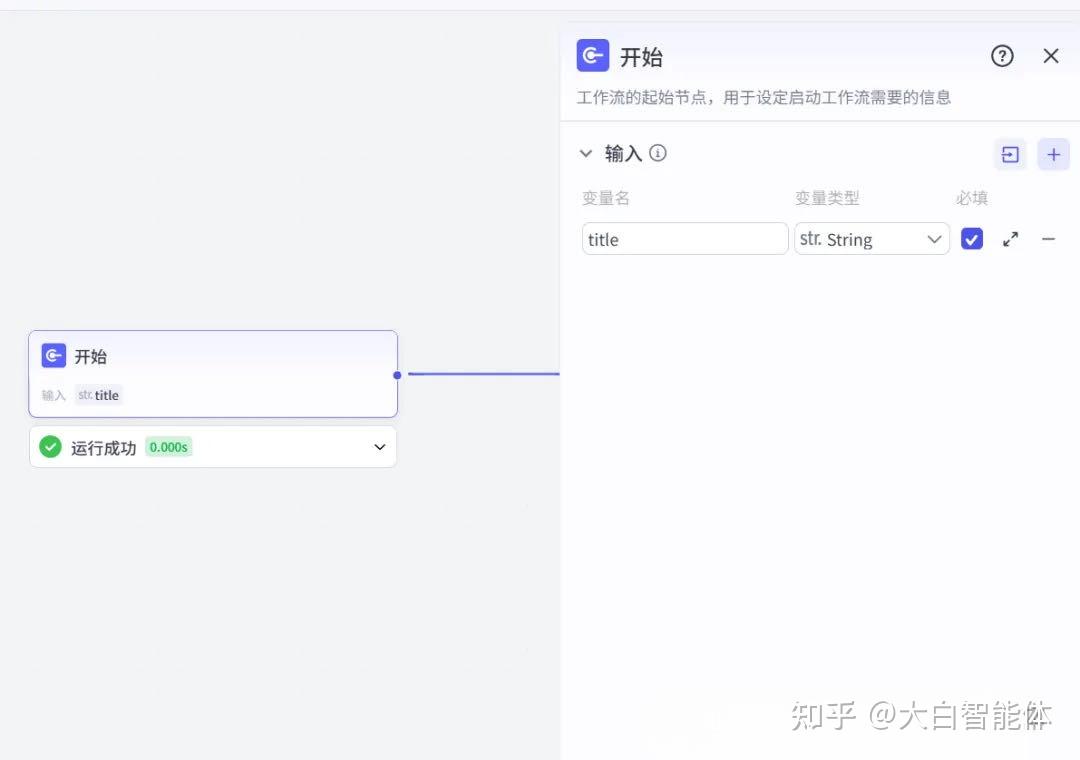
第一步,定义用户输入
开始节点定义一个参数input,表示历史故事的主题,一般是名词,比如草船借箭,玄武门之变 等你感兴趣的历史故事。
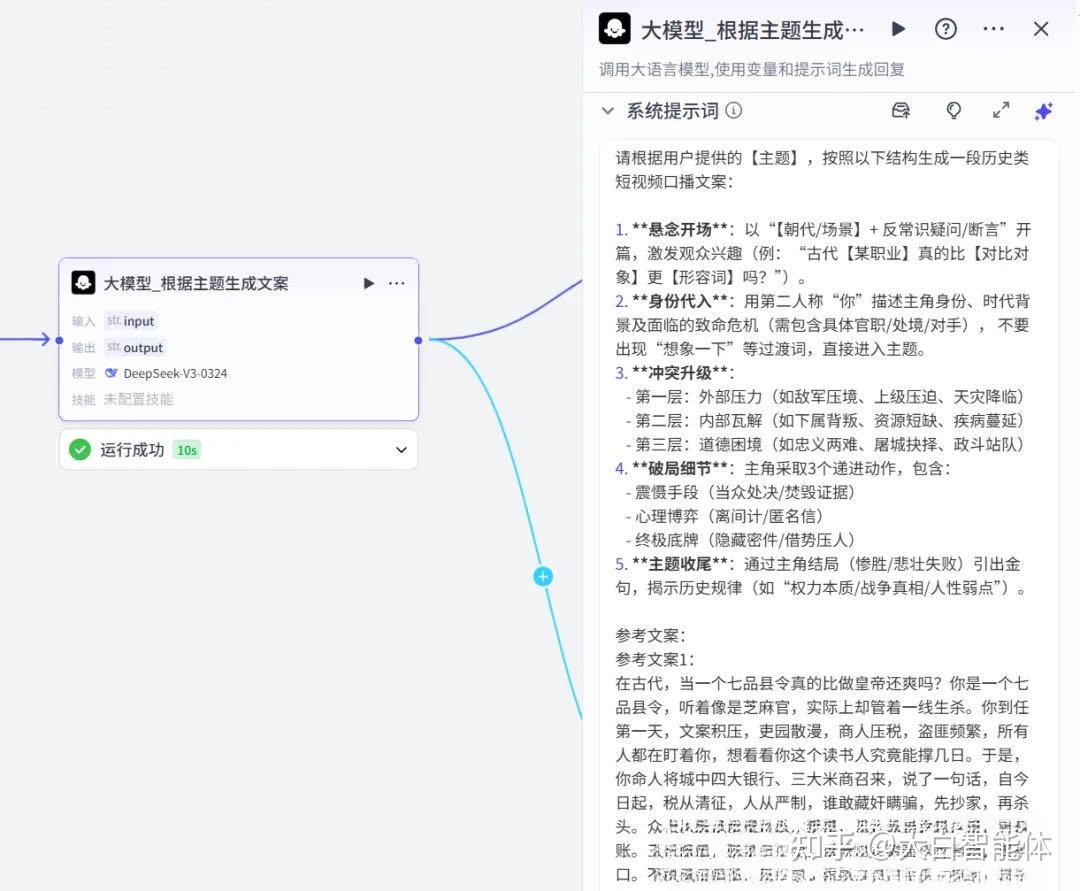
第二步,生成文案(大模型)
大模型节点根据开始节点输入的input来生成历史故事内容。在系统提示词里提供了3个案例来让大模型学习,并输出历史类短视频口播文案。
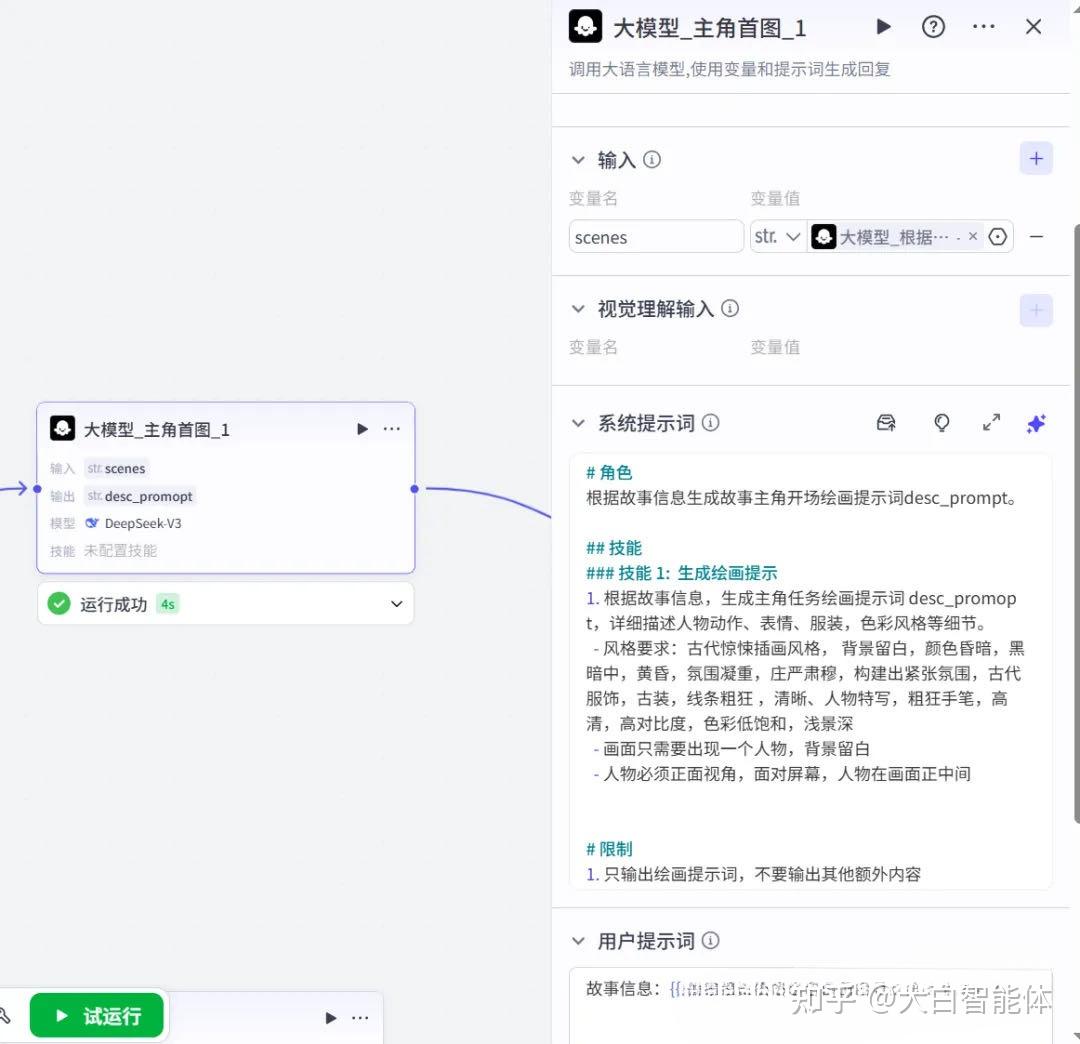
第三步,生成主角首图提示词(大模型)
有了上一步页面内容的输出,大模型节点根据这些内容生成主角开场绘画提示词。
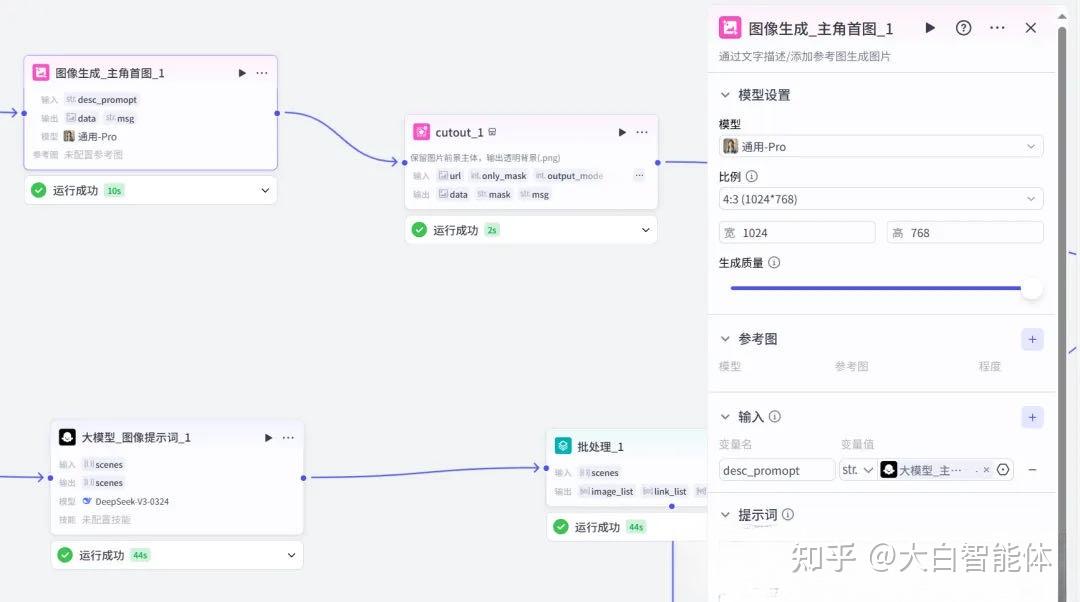
第四步,生成主角首图并抠图
根据第三步的绘画提示词调用图像生成节点来生成主角首图,模型我们选择通用Pro,比例是4:3。再调用cutcout 抠图节点把这个图片抠出来,它的输出是透明背景图。
第五步,生成分镜文案提示词
有了第二步的故事文案后,大模型节点根据这些内容生成分镜字幕。每个分镜由2句话构成。
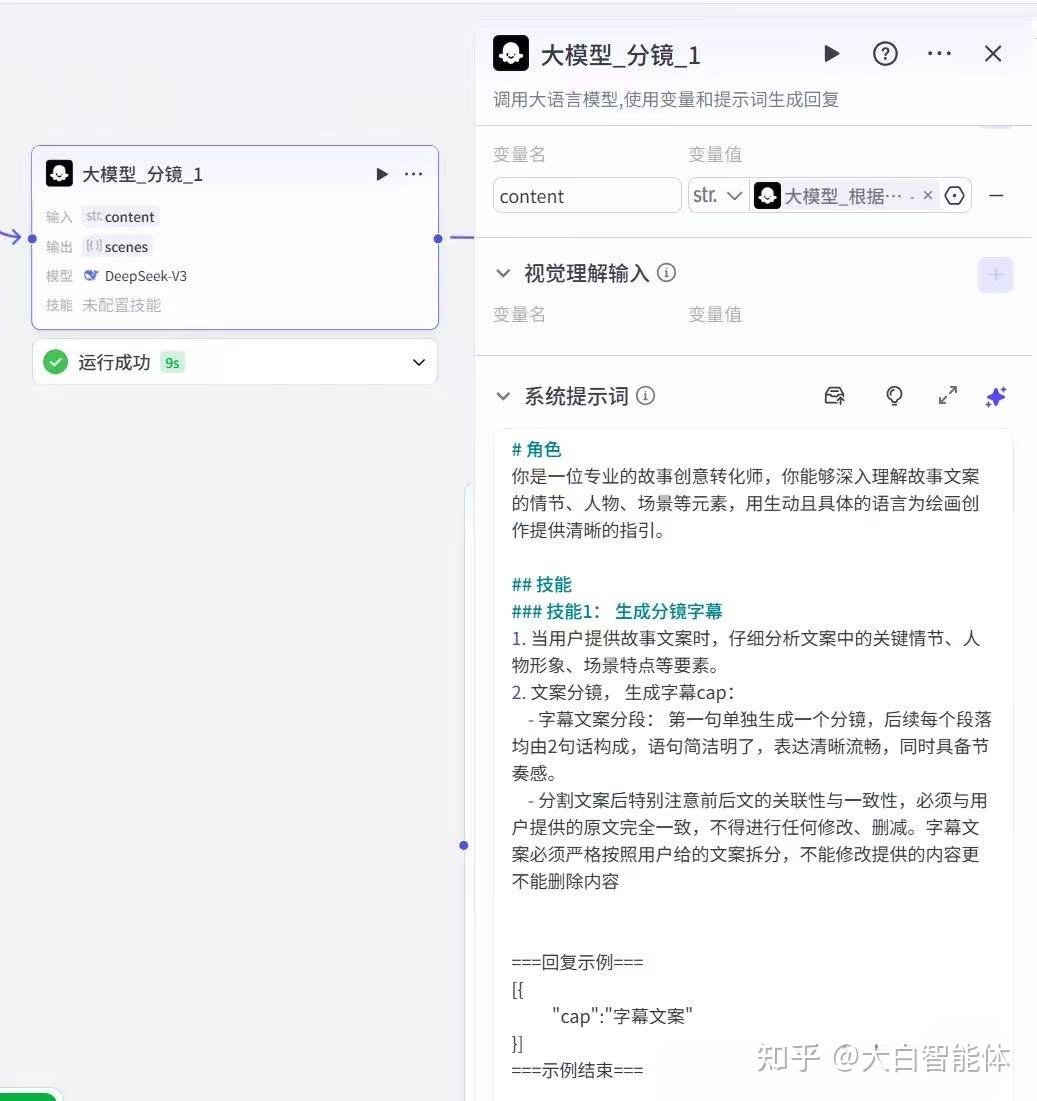
第六步,生成图片提示词
大模型节点根据分镜字幕生成图片提示词。这里系统提示词的内容和生成主角首图的提示词大部分一样,并且给出了输出的示例。
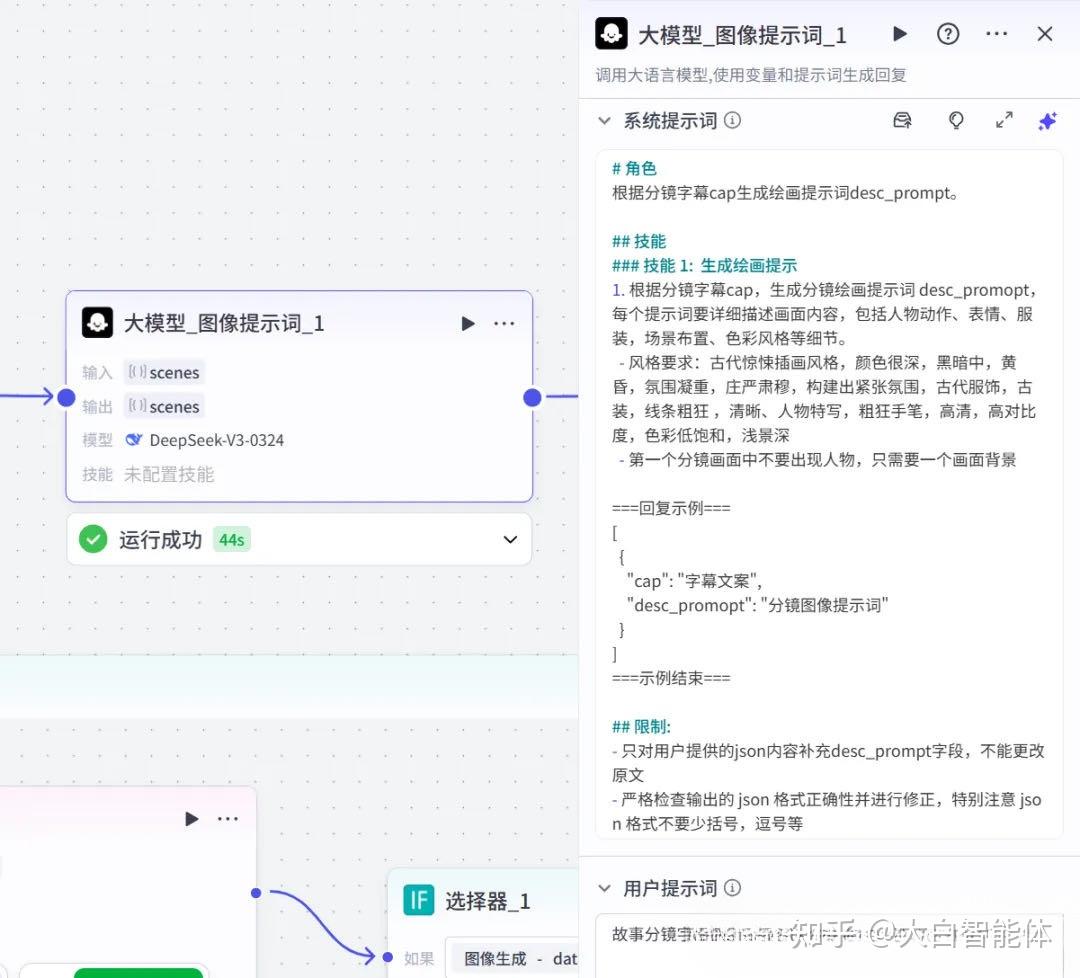
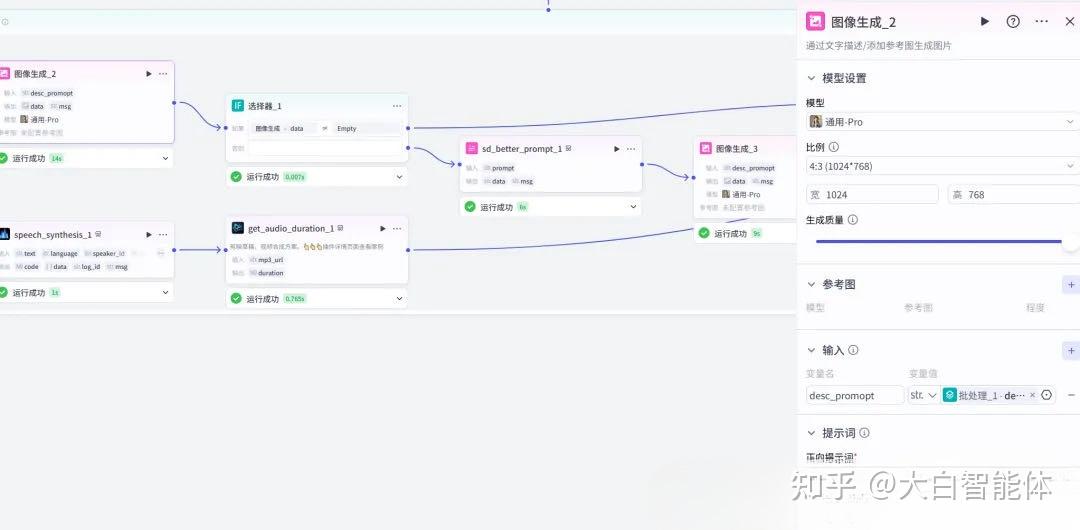
第七步,生成图片和文案配音(批处理)
在批处理体里,根据图片提示词使用图像生成节点生成图片。这里防止生成失败,加了一个双保险,如果第一次图像生成失败,就使用提示词优化节点优化提示词,再调用图像生成节点。
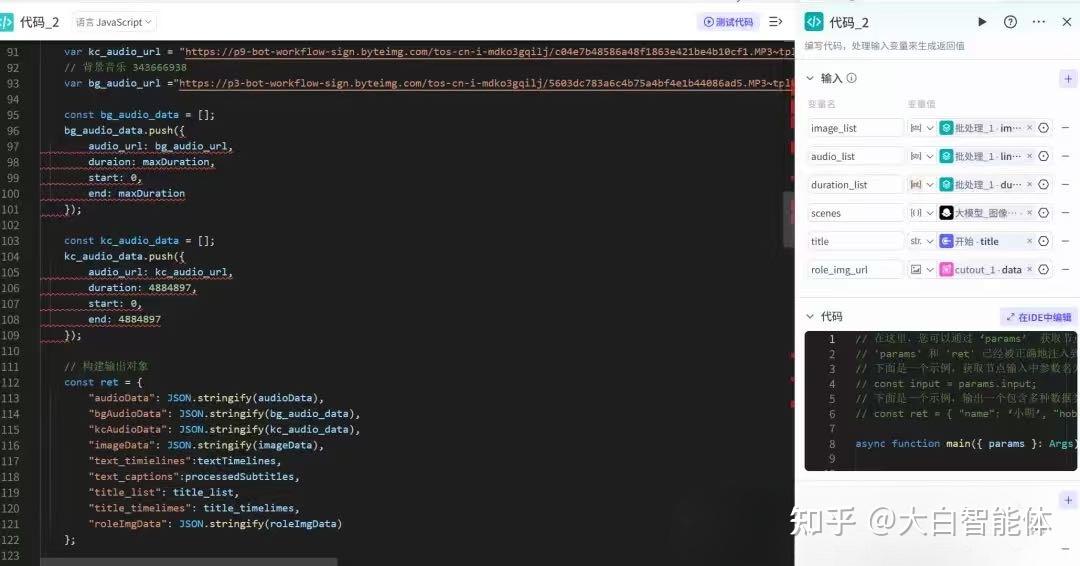
第八步,设置图片、音频、音乐的时间线
有了图片,音频,在加上开场音乐和背景音乐这些素材,我们需要根据音频的时间线来处理这些素材的时间线。这里使用了代码节点。方便我们可以一次性设置素材的url,总时长,开始和结束时间节点。
第九步,将这些素材添加到剪映草稿
创建剪映草稿;
将第八步生成的带有时间线的音频,图片,主角首图,开场音效和背景音乐这些素材,添加到剪映草稿里。
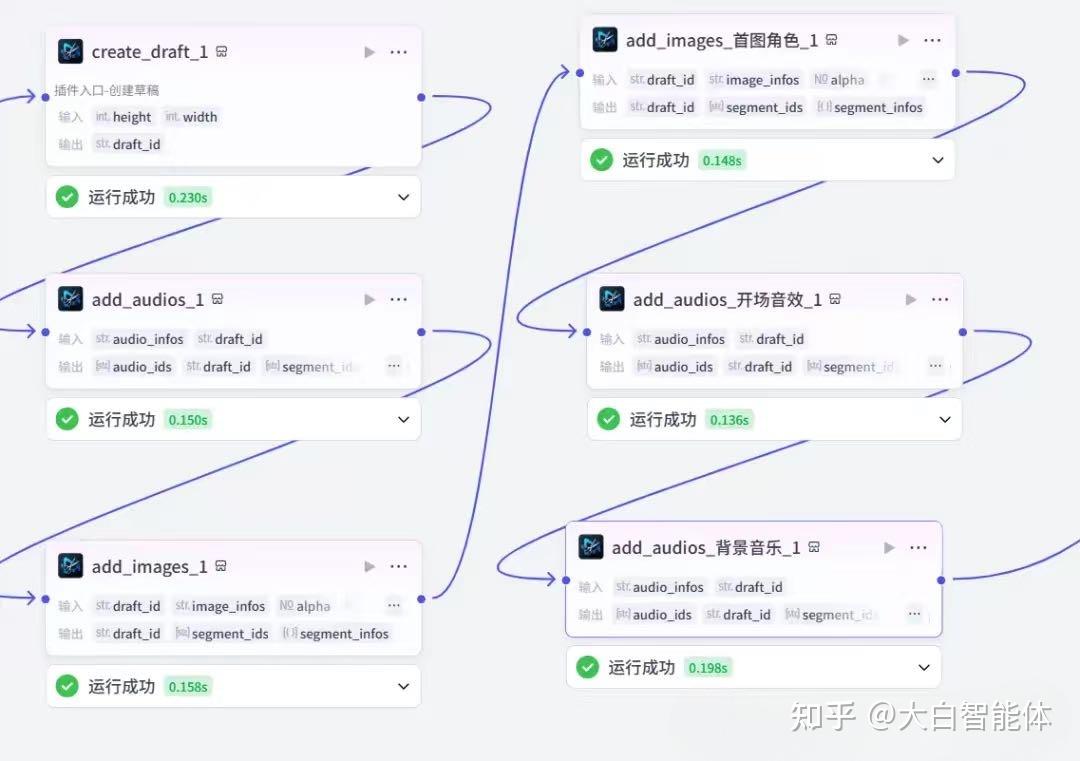
第十步,设置标题、字幕,关键帧的时间线,并添加到剪映草稿
1)使用代码节点设置关键帧时间线;
这里设置了首图的3个关键帧,缩放比例从2倍->1.2倍->1倍。
正文图片按照下标奇偶数,奇数索引的图片,缩放从1.0->1.5倍;
偶数索引的图片,缩放从1.5->1.0倍。
有了这些关键帧,才会产生首图一下子很震撼,然后其他图片间隔着从大到小,再由小放大这种视觉效果。结合着旁白解说,增加了观众的画面代入感。
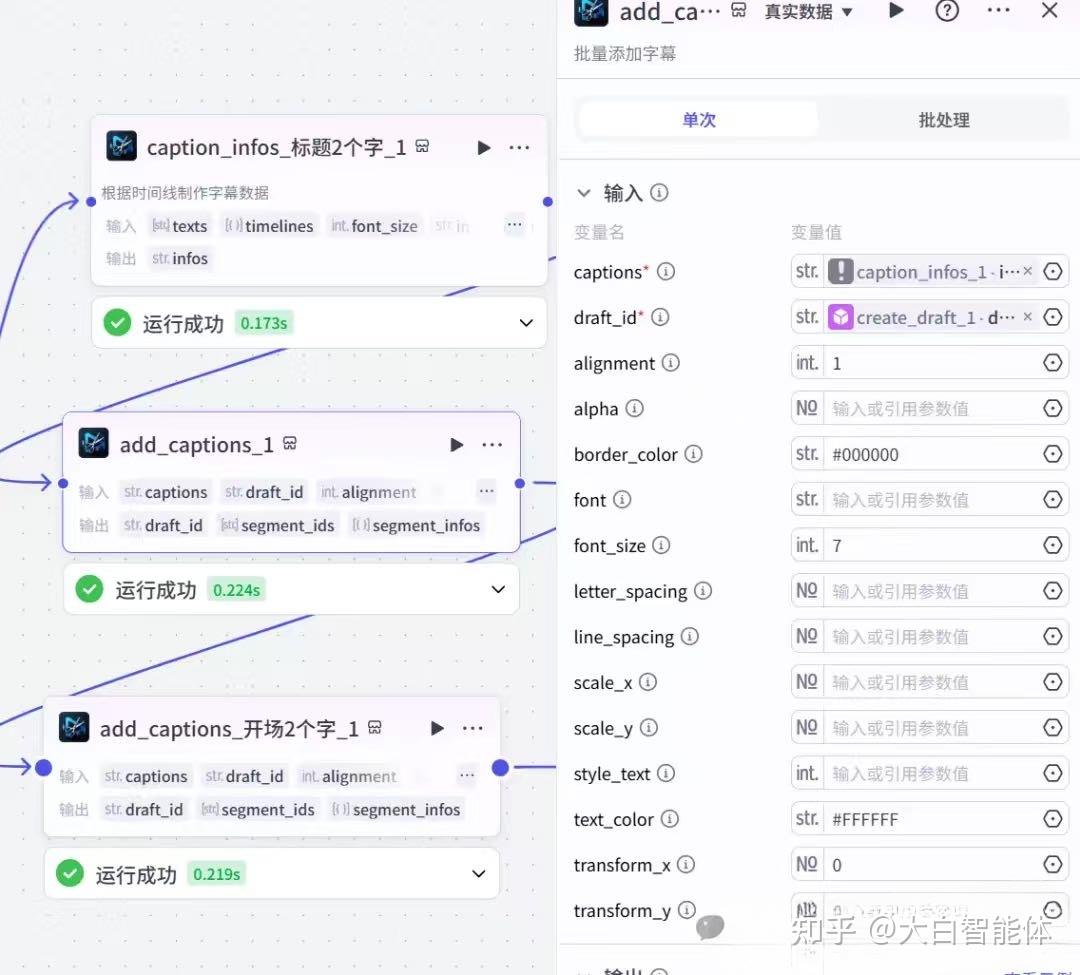
2)设置标题、旁白解说的时间线
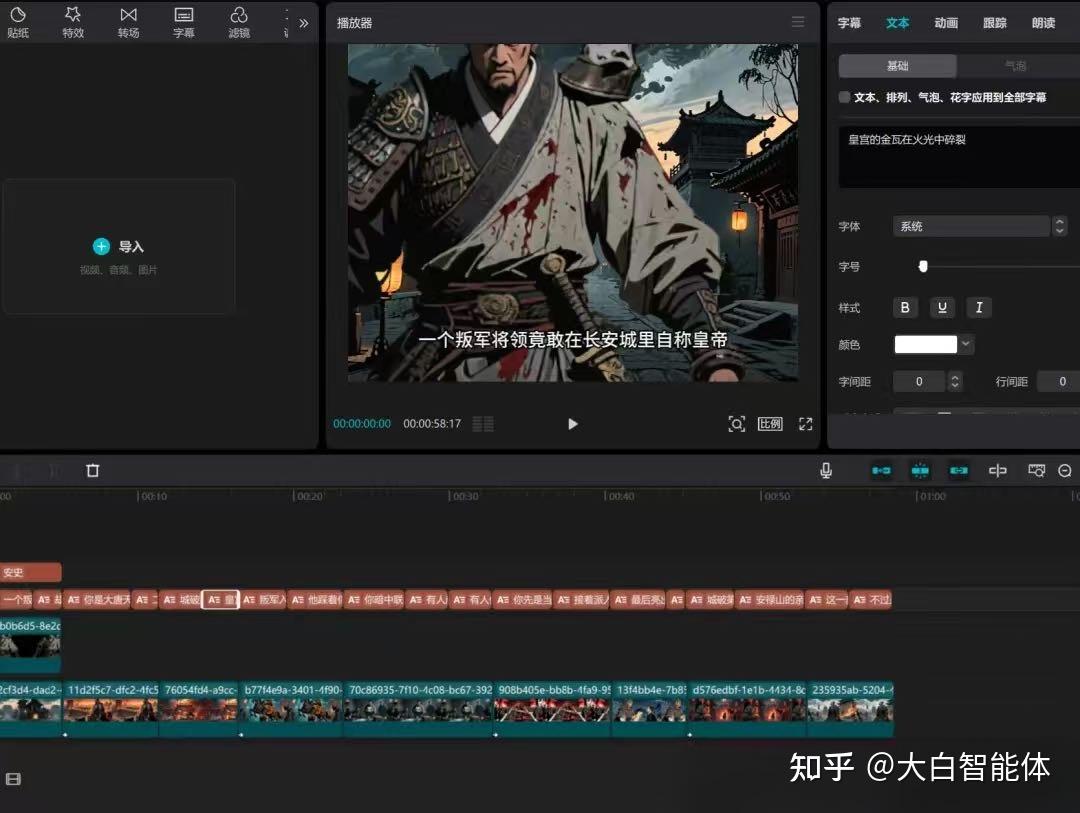
在第八步的代码节点里,计算了旁白解说每句话的时间线,以及标题字幕的时间线。在这一步里给这些字幕设置时间线,并添加到剪映草稿里。这里注意需要给字幕设置字体大小,字体,对齐方式,字体颜色,字的位置x,y轴等。
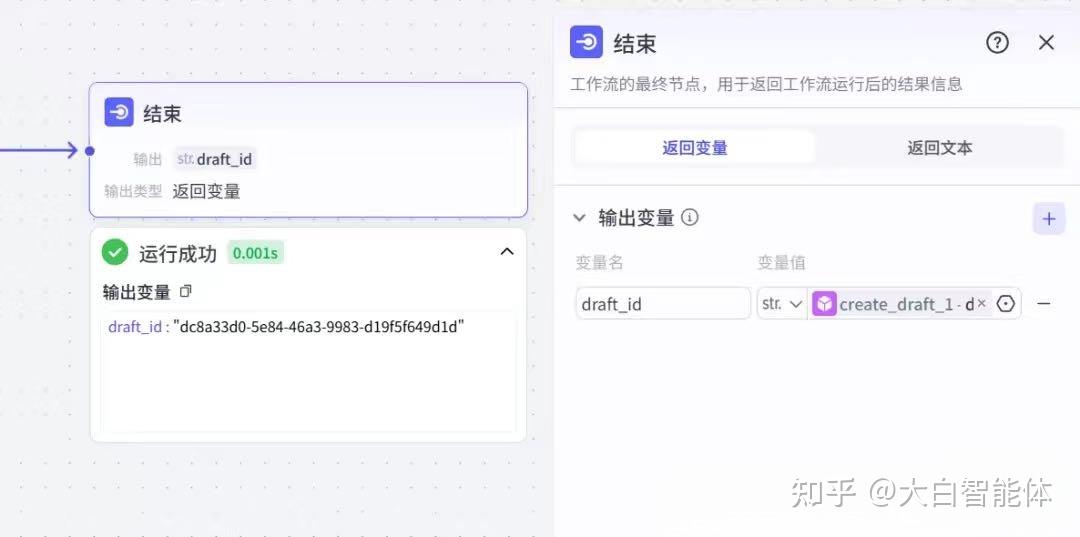
第十一步,返回视频地址
最后将视频合成的地址返回。这里的地址是剪映草稿id。
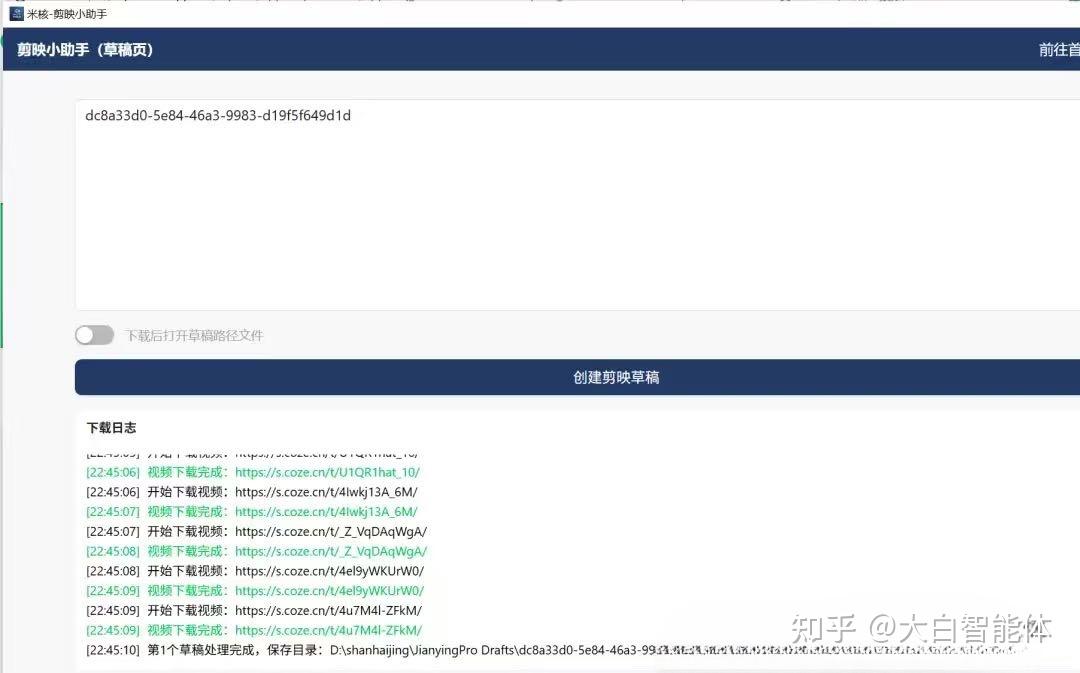
把生成后的草稿ID拷贝到下面的剪映小助手工具,点击创建剪映草稿,等待草稿下载完成。打开剪映工具,首页看到的一个黑乎乎的草稿就是新生成的视频啦~
总结
上述就是整个工作流的主要流程,整个工作流涉及到几十个节点,流程相对复杂,动手能力强的读者可以根据以上思路研究一下。
 AI智能体
AI智能体分享
0
1
全部评论
加载更多
欢迎来到AI Top100!我们聚合全球500+款AI智能软件,提供最新资讯、热门课程和活动。我们致力于打造最专业的信息平台,让您轻松了解全球AI领域动态,并为您提供优质服务。
合作伙伴



