
微软又开源了一个有意思的模型。
Phi-4-reasoning-vision-15B 是一个多模态推理模型,参数规模15B,主打轻量化。关键数字不是参数,而是训练用的token量——200B。不是万亿,是200B。这个量级放在今天的大模型赛道里,算是相当克制的。
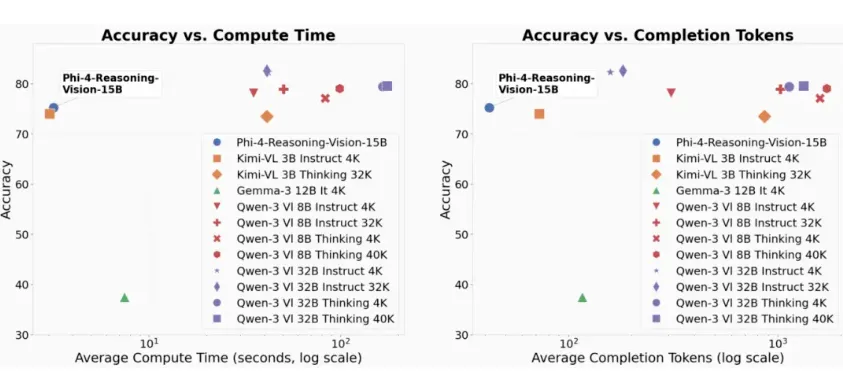
"小钢炮"是怎么做到的
业内大模型的训练数据量通常在万亿级别,token越多能力越强几乎成了共识。Phi-4-reasoning-vision的思路是反过来的:数据质量优先于数据数量。
研发团队在数据层面做了几件事:深度清洗开源数据,去掉低质量的噪声;生成定向合成数据,让模型在特定任务上有针对性;精密的领域数据配比,其中一个发现很有意思——增加数学数据的比例,可以同步提升计算机操作能力。这两个能力看似不相关,背后却存在某种内在关联。
这个策略的效果在基准测试中得到了验证。Phi-4-reasoning-vision在科学推理和屏幕定位任务上表现突出。对于一个15B规模的模型来说,这个成绩是超出预期的。
混合推理路径:简单和复杂任务分开处理
这个模型最实用的设计是混合推理路径。
面对图像描述、OCR这类简单任务时,模型默认走直接作答模式,响应快、不绕弯。遇到数学公式、科学图表这类复杂逻辑任务时,模型会自动调用结构化的思维链路径,确保答案的准确性。用户也可以通过特定的引导词手动切换两种模式。
这个设计的本质是按需分配算力。不是所有问题都需要深度思考,但大模型通常把每个问题都当成复杂问题来处理,效率上有浪费。Phi-4-reasoning-vision在架构层面解决了这个问题——模型自己判断这个任务需要多深的思考。
SigLIP-2编码器带来的感知能力
另一个关键组件是SigLIP-2动态分辨率编码器。这个编码器让模型对高分辨率截图中的细小元素具有很强的感知能力——按钮、输入框、下拉菜单这些UI元素,都能精准识别和定位。
这个能力直接指向一个应用场景:计算机操作助手(CUA)。也就是说,Phi-4-reasoning-vision可以作为AI编程助手的一部分,帮用户自动操作网页或手机界面——看到按钮就点击,看到输入框就填内容,而且是在高分辨率截图的精细感知下完成的。
这比简单的OCR前进了一步:不只是读懂屏幕上写了什么,而是知道屏幕上的每个元素是什么、有什么用。
轻量化模型的价值在哪里
Phi-4-reasoning-vision的开源,对应的市场需求很明确:不是所有人都需要跑千亿级参数的大模型,很多实际任务不需要那么强的能力,但需要在本地或资源受限的环境下高效运行。
15B规模意味着可以在消费级GPU上运行,200B token训练则保证了推理效率不会太低。对于开发者来说,这是一个可以在自己机器上跑起来、做实操项目的选择,而不是只能调用云端API。
微软对这款产品的定位是"紧凑型模型证明更小更快也能更强"。从技术路径来看,这个证明是成立的。但轻量化模型的局限也要看到——在需要极强推理能力的复杂任务上,它和大模型之间仍有差距。
轻量化和大模型不是替代关系,而是不同场景下的分工。Phi-4-reasoning-vision的价值,在于把多模态推理能力的门槛往下拉了一截。
AITOP100-AI资讯频道将持续关注AI行业新闻资讯消息,带来最新AI内容讯息。
想了解AITOP100平台其它版块的内容,请点击下方超链接查看
AI创作大赛 | AI活动 | AI工具集 | AI资讯专区 | AI小说
AITOP100平台官方交流社群二维码:











