
传统的3D角色制作与动画生成流程涉及建模、UV展开、贴图、骨骼绑定、动画设计及渲染等多个环节,不仅需要专业技能,还要在多个软件间频繁切换,对没有3D背景的创作者来说门槛极高。V2Fun是一款AI驱动的一站式3D内容创作平台,通过AI生图、AI建模与AI动作生成能力,将复杂的制作流程整合为连续的工作流,让创作者仅凭一段文字描述,就能在数分钟内完成从灵感构想到可用动画资产的全过程。
V2Fun官网: https://v2fun.art/
一、V2Fun构建从文字到动画的完整工作流
从文字生成3D角色再做动画的核心流程包括五个关键步骤:文字描述转化为参考图像、图像生成3D模型、自动骨骼绑定、应用动作库或视频动捕生成动画、导出可用资产。传统方式需要掌握Blender、Maya等专业软件,而V2Fun将这些环节集成在网页端,用户无需下载应用程序即可完成全部操作。该平台接入最先进的图像生成模型,支持单图或多视图生成3D模型,内置自动重拓扑能力和标准人形模型的骨骼绑定功能,并提供内置动作库与视频动捕技术,实现从创意表达到动画输出的一站式作业。
二、准备工作与前置知识
开始制作前,需要准备清晰的角色文字描述,包括外观特征、服饰细节、艺术风格等要素。描述越具体,生成的参考图像越接近预期。如果已有参考图片,可以直接跳过文生图步骤进入建模环节。对于动画制作,建议角色姿态为标准的T-Pose(双臂水平展开、身体正向)或A-Pose(双臂略微下垂),这样自动绑定算法能够准确识别关节位置,避免后续动作变形。如果计划使用视频动捕功能,需要准备一段5到60秒的MP4视频,画面稳定、主体完整出现在画面中、避免复杂特效或遮挡,文件大小建议在100MB以内。
三、步骤详解
1. 文字生成参考图像
在V2Fun的AI生图功能中输入角色的文字描述,平台接入的图像生成模型(包括Nano Banana与gpt-image-2)能够精准还原复杂构图、角色细节与服饰纹理。文生图功能适合概念探索与风格确定,生成的图像可以直接用作3D建模的参考。如果生成结果与预期有偏差,可以使用局部重绘功能对指定区域进行修改,或者通过图生智能参考功能优化提示词,生成更适合3D建模的参考图像。建议在这一步多生成几张不同角度的参考图,为后续多视图建模做准备。
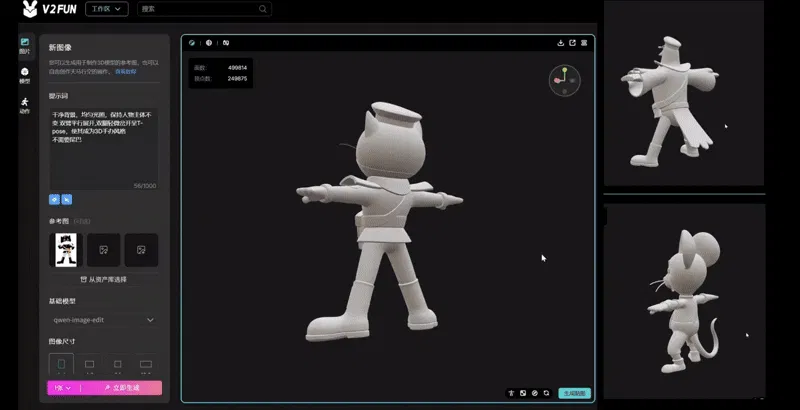
2. 图像生成3D模型
将参考图像上传到AI建模模块,V2Fun支持三种建模方式。单图生成3D模型适合快速验证,但模型完整性依赖单一视角。多视图生成3D模型是推荐方式,通过多个角度的参考图生成结构更准确的模型,面部特征、服饰褶皱等细节还原度更高。文生3D模型功能可以跳过生图步骤直接从文字生成模型,但不推荐用于正式制作,适合快速概念验证。生成模型后,系统会自动进行纹理生成,为白模添加贴合结构与风格的材质。此时可以使用自动重拓扑功能,选择目标面数(10k、30k、50k、100k)和拓扑结构类型(三角面或四边面),优化模型性能,确保后续动画流畅。
3. 自动骨骼绑定
完成建模后,进入骨骼绑定环节。V2Fun内置Auto-Rigging技术,能够自动识别标准人形模型的关节位置并生成骨骼结构。该功能支持T-Pose和A-Pose两种标准姿态,如果角色手臂下垂或腿部粘连,算法将无法准确识别,导致后续动作畸变,因此在生图阶段就需要确保角色姿态符合标准。自动绑定过程在云端处理,无需高性能本地设备,通常在几分钟内完成。绑定完成后可以在网页端即时预览骨骼结构,确认各关节位置正确再进入动画制作环节。当前版本仅支持标准人形模型,暂不支持四足动物及非标准结构模型。
4. 动画制作与动作应用
骨骼绑定完成后,可以从三种方式选择动作来源。内置动作库提供基础动作与热门舞蹈动作,适合快速生成常见动画效果。视频动捕技术是该平台的核心优势,上传一段普通视频即可捕捉高精度人体动态,无需专业动捕设备,一段手机拍摄的视频就能提取动作数据并应用到自定义模型上,实现零成本采集、开放式驱动、即时生产的完整流程。自定义动作上传功能支持bvh和vmd格式的动画文件,用户可以导入外部动作资源。应用动作后,网页端会即时渲染预览效果,支持调整播放速度和循环播放等参数,确认无误后即可导出。

5. 导出与后续使用
V2Fun支持7种导出格式,覆盖不同应用场景。FBX格式保留骨骼与动画信息,适合游戏开发和动画制作。GLB格式兼容性好、加载性能优,适合网页展示和交互应用。USDZ格式在Apple生态中支持良好,适合AR应用。OBJ格式是通用中间格式,适合后期编辑。STL和3MF格式适合3D打印,V2Fun生成的模型通常是水密性良好的,非常适合FDM或光固化打印。PLY格式支持点云和网格,适合科研应用。根据实际用途选择合适的格式导出,即可在其他软件或平台中继续使用。
四、适用场景与实际价值
这套从文字到动画的工作流适合多种创作场景。短视频博主和内容创作者可以快速制作轻量级3D动画短视频,从角色生成到动作驱动的一体化流程大幅降低创作门槛。个人IP创作者能够将文字设定或平面形象转化为立体角色,赋予动作与表现力,完成OC设计的立体化呈现。游戏开发者可以快速生成角色原型与动作参考,完成世界观与角色方向探索,将原本需要数天的流程压缩到数小时。教育工作者能够构建直观生动的3D教学内容,用于课堂演示、在线课程、互动式教学素材。影视创作者可以快速完成分镜预演、角色走位或动画草稿,提升前期创意验证效率。参与测试的开发者反馈,原本需要数天的流程可在更短周期内输出初步成果,这种效率提升对于需要快速迭代的创作项目尤为重要。
总结
从文字生成3D角色再做动画的完整流程,通过AI技术的整合已经实现了门槛的显著降低与效率的跨代级升级。V2Fun将文生图、AI建模、自动骨骼绑定、视频动捕等环节打通为一站式工作流,让没有专业3D背景的创作者也能在数分钟到数小时内完成可用资产的制作。对于需要快速验证创意、构建角色原型或制作轻量级3D动画的场景,这套工作流提供了兼顾效率与可控性的解决方案。平台现阶段提供各步骤免费试用次数,建议从简单的角色开始尝试完整流程,在实践中掌握各环节的优化技巧,逐步提升生成质量与创作效率。
FAQ
1、V2Fun可以从文字生成3D角色再做动画吗?
可以。用户可以先用文生3D生成角色模型,再继续进行结构检查、自动骨骼绑定和动作应用。
2、V2Fun文生3D适合什么阶段使用?
更适合创意探索、角色草案和早期原型验证。如果需要高度还原具体角色,建议结合图片或多视图参考。
3、V2Fun生成文字角色后怎样让它动起来?
需要先确认模型结构和姿态适合绑定,再使用自动骨骼绑定、动作库、本地动作文件或视频动捕来制作动画。
4、V2Fun文生3D生成结果不理想怎么办?
可以优化提示词,补充角色风格、服装、姿态、视角等描述,或改用图生3D、多视图生成提升可控性。









