

过去一年,AI Agent 的讨论越来越热:能不能自己拆任务、调工具、写文件、查网页、修错误,正在成为大模型从“会聊天”走向“能办事”的关键能力。
但行业里一直有个尴尬问题:
一个 Agent 任务失败了,到底是模型不够强,还是运行框架没搭好?
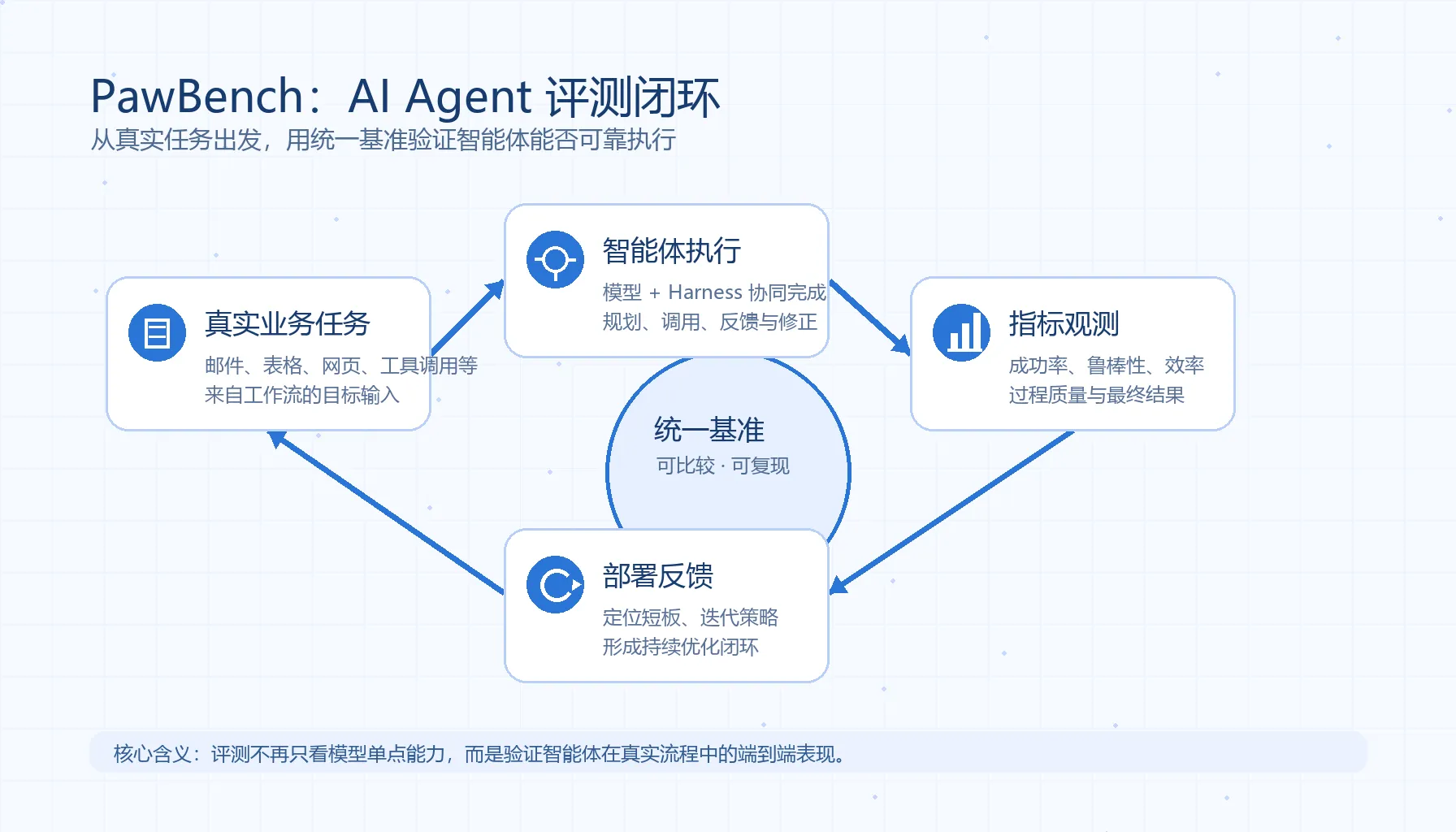
通义实验室近日推出并开源的通用智能体评测基准 PawBench v1.0,正是为了解决这个问题。它面向个人助理与通用智能体场景,把底座模型、运行框架(Harness)和真实任务放到同一个评测体系里,试图给 AI Agent 能力评估提供一把更统一、更可复盘的尺。ref_1
1. PawBench 评的不是“单个模型”,而是“模型 × 框架 × 任务”
传统大模型评测,通常更像是在问:
这个模型会不会答题?推理强不强?知识多不多?
但 Agent 场景的问题复杂得多。模型不只是生成答案,还要理解目标、规划步骤、调用工具、读写文件、处理异常、确认结果是否真实落地。
这意味着,Agent 的最终表现并不完全等于模型能力。
PawBench 的关键创新在于,它不把评测对象简化成“模型排行榜”,而是把三件事放在一起看:
- 模型:底座大模型本身的理解、推理、规划与生成能力;
- Harness:智能体运行框架,包括工具暴露、上下文组织、状态管理、异常恢复等;
- 任务:来自真实工作流的 Agent 任务,覆盖不同场景、复杂度与执行环境。
换句话说,PawBench 更像是在评估:
一个模型,在某个 Agent 框架里,面对某类真实任务时,到底能不能稳定完成?
这比单纯比较模型分数,更接近企业真正关心的问题。

2. 为什么 Harness 会变得这么重要?
在 Agent 系统里,Harness 可以理解为“把模型能力组织起来的工程底座”。
如果说模型是发动机,那么 Harness 就是变速箱、方向盘、刹车、仪表盘和安全系统。发动机再强,如果整车工程不稳定,也很难在复杂路况里跑得远。
PawBench 的公开信息显示,v1.0 构建了由多个模型、多个 Harness 与真实任务组成的交叉评测矩阵,并保留执行轨迹、评分产物和环境快照,方便开发者复盘问题。[ref_5]
这类设计的价值在于:它不只给出“谁分数高”,还帮助回答更细的问题:
- 是模型没有理解任务,还是框架没有把上下文讲清楚?
- 是工具能力不足,还是工具太多导致模型选错?
- 是任务执行失败,还是产物没有被正确校验?
- 是模型无法恢复,还是框架没有提供足够的纠偏机制?
这就是 Agent 评测从“结果排名”走向“问题诊断”的关键一步。
3. 一个重要信号:Agent 能力进入“系统工程竞争”
PawBench 相关报道提到,在同一模型下,不同 Harness 之间可能产生明显分差;优秀的 Harness 甚至可能让相对小的模型在部分组合里获得更好的任务表现。ref_4
这传递出一个非常重要的行业信号:
AI Agent 的竞争,正在从单纯的模型竞赛,转向模型能力与系统工程能力的综合竞争。
过去,大家更关注模型参数、上下文长度、推理能力、多模态能力。现在,当模型能力逐步逼近可用门槛,工程层面的差异会被放大:
- 工具是否在正确时机提供给模型;
- 上下文是否结构化、完整且不过载;
- 任务状态是否可追踪;
- 中间步骤是否有监控与校验;
- 失败后是否能重试、回滚或换路径;
- 最终结果是否真的生成、保存并满足要求。
这些能力,很多并不来自模型参数本身,而来自 Agent 框架的设计质量。
4. PawBench 给开发者的四个启发
从公开资料看,PawBench 不仅是一个评测集,也在推动行业形成更清晰的 Agent 工程方法论。对开发者和企业团队来说,至少有四点值得关注。
第一,充分告知:让模型知道自己在哪里、能做什么
很多 Agent 失败,不是模型完全不会,而是它拿到的信息不完整。
例如:当前工作区在哪里?用户文件有哪些?哪些目录可以写?工具调用有什么约束?任务完成后需要交付什么格式?
如果这些信息散落在长上下文中,模型就容易漏掉关键限制。更好的方式是把运行环境、工具能力、任务状态结构化地交给模型,让它在每一步都能清楚判断。
第二,按需装备:工具不是越多越好
Agent 框架常见误区是:把所有工具一股脑塞给模型。
但工具过多会带来三类问题:选择成本上升、上下文被挤占、模型注意力分散。真正可靠的 Agent 系统,应该根据任务阶段动态暴露工具,让模型在正确时机使用正确能力。
第三,主动监控:不能只听模型说“我完成了”
Agent 很容易出现一种问题:嘴上说完成了,但文件没写、路径不对、结果为空、格式不符合要求。
因此,Harness 需要有独立的质量检查机制。比如检查产物是否存在、内容是否有效、表格是否完整、引用是否可追溯、输出是否满足用户要求。
这也是 PawBench 这类评测的价值:它让“虚假完成”“产物缺失”“执行轨迹异常”等问题有机会被系统性暴露。
第四,弹性恢复:真实任务里,失败是常态
生产环境中的 Agent 不可能永远一次成功。
工具会报错,网页会变化,文件格式会异常,上下文会超长,模型可能走偏。关键不在于永不失败,而在于失败后能不能恢复:
- 工具调用失败后是否能重试;
- 路径错误后是否能重新定位;
- 上下文过长后是否能压缩摘要;
- 连续失败后是否能换方案;
- 最终交付前是否能自检。
这类恢复能力,往往决定 Agent 从 Demo 走向生产的可靠性。
5. 对企业来说,PawBench 的价值不只是“看榜单”
如果只是看一个排行榜,PawBench 的意义会被低估。
它真正重要的地方,是让企业在评估 Agent 能力时,有机会从三个层面拆解问题:
- 选模型:哪个模型更适合自己的业务任务?
- 选框架:哪个 Harness 能更稳定地释放模型能力?
- 做诊断:失败到底发生在理解、规划、工具调用、状态管理,还是结果校验?
对企业落地 AI Agent 来说,这比“某个模型综合分更高”更有价值。因为真实业务追求的不是单次炫技,而是稳定、可控、可复盘、可持续迭代。
6. 结语:Agent 的下一阶段,是把智能变成可靠生产力
PawBench 的推出,说明行业对 AI Agent 的关注正在变得更务实。
过去我们问:“模型聪不聪明?”
现在我们更需要问:
在真实工作流里,它能不能稳定完成任务?出了问题能不能定位?换一个框架会不会更好?系统能不能持续改进?
这也是 Agent 从实验室走向办公桌、从演示视频走向企业流程时必须回答的问题。
通义实验室推出 PawBench,本质上是在提醒行业:
通用智能体不是单点模型能力的展示,而是模型、框架、工具、任务和评测体系共同构成的系统工程。
有了统一评测基准,AI Agent 的能力讨论才可能从“感觉很强”走向“可度量、可诊断、可优化”。
而这,可能正是 Agent 真正走向规模化落地的开始。
参考资料
- [ref_1] 搜狐/财法观天下:《通义实验室发布通用智能体评测基准PawBench》,2026-06-05。
- [ref_2] 搜狐/钛媒体快报:《通义实验室推出通用智能体评测基准PawBench》,2026-06-05。
- [ref_3] CSDN:《PawBench深度解析:Harness工程对智能体表现的影响到底有多大?》,2026-06-06。
- [ref_4] 腾讯网:《阿里发布智能体基准PawBench:优秀框架可助小模型「下克上」》,2026-06-05。
- [ref_5] 同花顺/AI观察:《PawBench 发布:首个联合评估通用智能体“模型+框架”的评测基准》,2026-06-05。









