

国产大模型的竞争,正在从“参数规模叙事”转向“真实任务能力、长上下文效率和智能体执行力”的综合较量。
本周,MiniMax 正式发布新一代基础模型 MiniMax M3。按照 MiniMax 官方博客披露的信息,M3 是一次面向智能体、编程、多模态和长上下文场景的系统级升级:支持 100 万 Token 上下文窗口,引入 MSA 稀疏注意力机制,具备原生多模态能力,并在 Coding、Agent、多轮推理和长文档处理等任务中显著增强。
最有传播度的一点,是官方提到 M3 在 SWE-Bench Pro 等特定编程基准上超过 GPT-5.5 和 Gemini 3.1 Pro。这一表述很重磅,但也需要准确理解:它并不意味着 MiniMax M3 在所有能力上“全面超越”海外闭源模型,而是在特定任务、特定评测维度上,国产模型已经开始进入全球第一梯队。
这也是本文更想讨论的重点:M3 的意义,不只是一个模型跑分,而是国产大模型正在补齐“长上下文 + 工具调用 + 多模态 + 智能体执行”的关键能力组合。
一、M3为什么值得关注:不是单点升级,而是面向Agent时代的底座模型
过去一年,大模型行业的竞争焦点发生了明显变化。
早期大家比拼的是参数规模、通用问答、中文理解和内容生成;后来进入代码、数学、推理能力竞赛;而现在,真正有生产力价值的模型,必须能处理更长上下文,理解多模态信息,调用工具执行任务,并在复杂工作流中保持稳定。
MiniMax M3 的产品定位,正是朝这个方向推进。
从官方披露看,M3 支持 1M Token 长上下文,强调 Coding 和 Agent 能力,并具备原生多模态输入输出基础。对企业用户和开发者来说,这意味着模型可以更好地处理大型代码仓库、长文档、复杂项目资料、多轮任务链路和跨模态内容。
如果说上一代模型更像“强问答助手”,那么 M3 更像是面向 Agent 应用的“大脑底座”。它不只是回答问题,而是要理解任务、读取上下文、拆解步骤、调用工具、生成结果,并在反馈中持续修正。
二、百万上下文与MSA:长任务能力的底层支撑
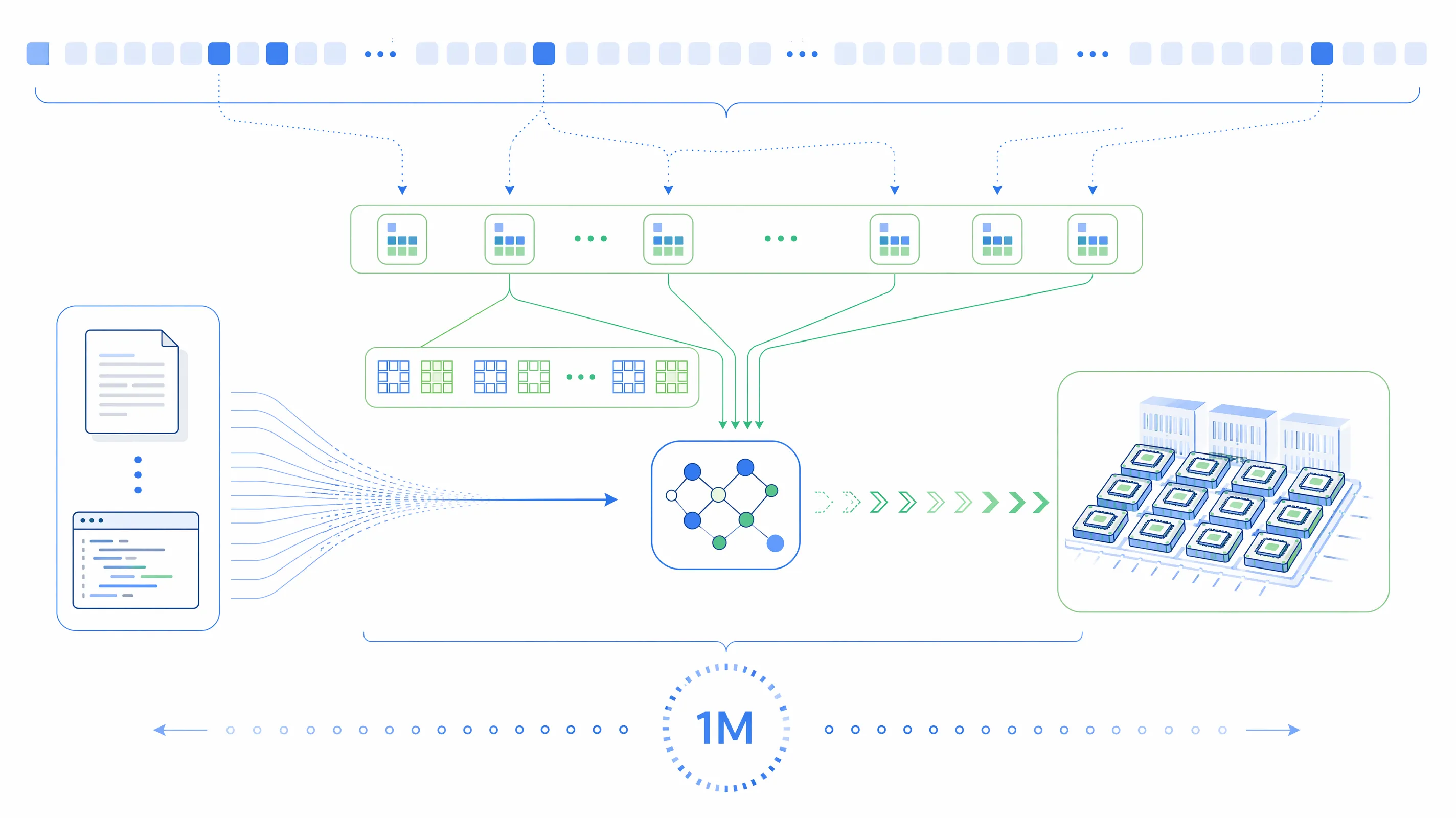
长上下文是 M3 发布中最重要的关键词之一。
100 万 Token 上下文窗口,意味着模型理论上可以一次性处理超长文档、完整项目资料、复杂会议记录、产品手册、合同库、研究报告,甚至较大规模代码仓库。对于企业场景,这个能力非常关键,因为真实工作从来不是单个问题,而是大量材料、历史上下文和约束条件叠加之后的综合判断。
但长上下文并不只是“塞得多”。真正难的是如何在大量上下文中找到关键内容,并以可接受成本完成推理。
MiniMax M3 引入的 MSA 稀疏注意力机制,正是为了解决这个问题。简单理解,传统模型在处理长文本时,计算成本容易随上下文长度快速膨胀;稀疏注意力则试图让模型更高效地关注关键片段,在长上下文和推理效率之间取得平衡。
这对国产模型尤其重要。未来大模型进入企业,成本不是小问题。一个模型如果只能在演示中处理长文本,却无法以合理成本大规模调用,就很难成为生产力工具。M3 对长上下文效率的强调,说明模型竞争已经从“能力可达”进一步进入“能力可用”。
三、Coding与Agent:国产模型正在进入真实工程任务
M3 最受关注的成绩,来自编程与智能体相关评测。
官方信息显示,M3 在 SWE-Bench Pro 等编程任务基准上表现突出,并在特定指标上超过 GPT-5.5 和 Gemini 3.1 Pro。SWE-Bench 类评测之所以重要,是因为它不只是考模型会不会写一段代码,而是考模型能否理解真实软件仓库、定位问题、修改代码、运行验证并解决工程任务。
这恰好代表了大模型应用的下一阶段:从“生成内容”走向“完成任务”。
对企业来说,Coding 能力并不只服务程序员。它背后体现的是模型对复杂系统、工具调用、逻辑约束、错误反馈和多步骤执行的理解能力。一个擅长工程任务的模型,往往也更适合做数据分析 Agent、运维排障 Agent、流程自动化 Agent 和办公智能体。
换句话说,M3 在 Coding 和 Agent 方向的提升,不只是技术圈新闻,也可能影响企业 AI 应用落地的速度。因为企业真正需要的不是会聊天的模型,而是能接入系统、理解流程、执行动作、交付结果的智能体。
四、原生多模态:从文本助手走向综合感知模型
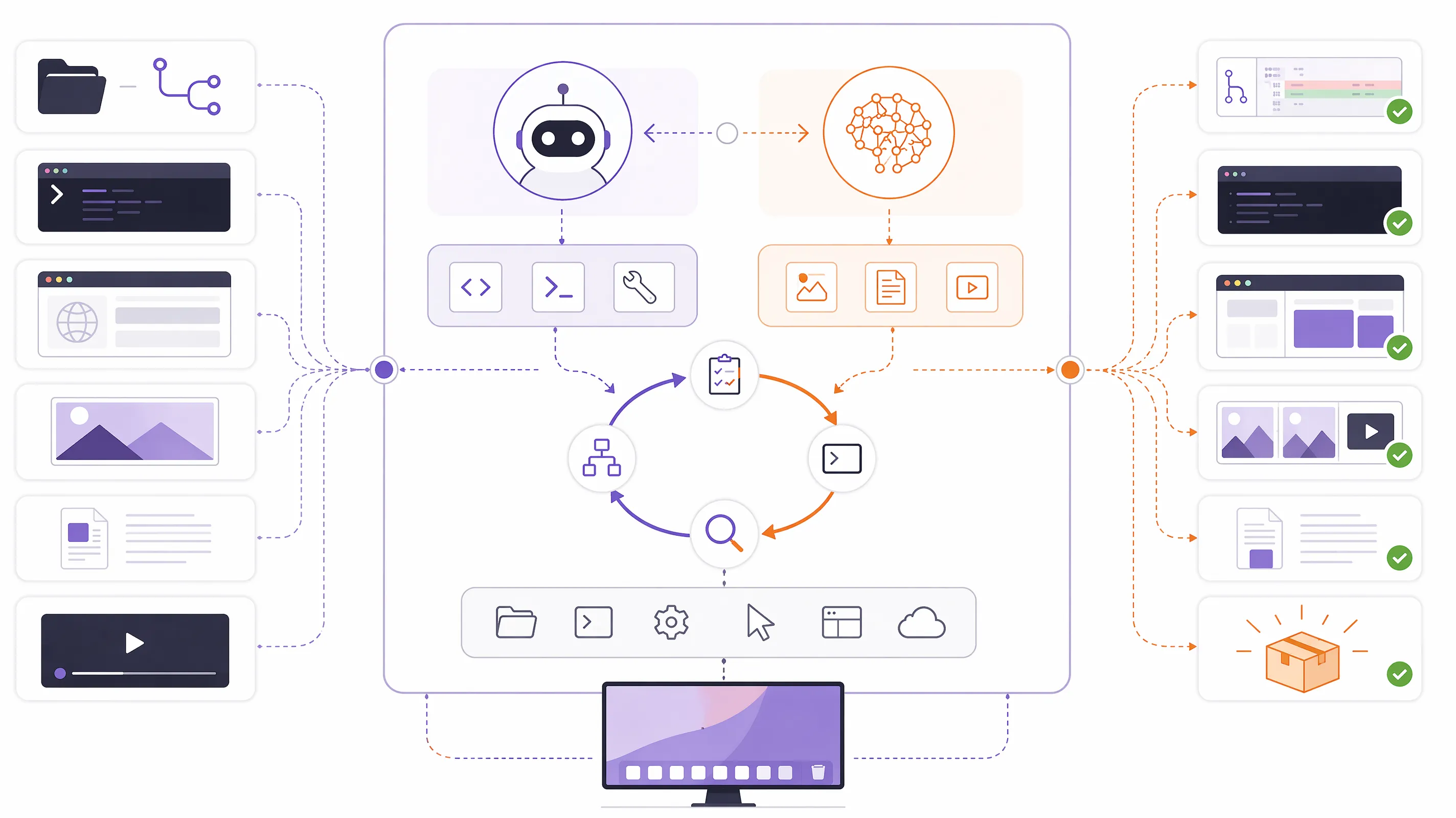
MiniMax M3 还强调原生多模态能力。
这意味着模型不只是处理文本,还要理解图像、文档、界面、视频帧等更丰富的信息形态。对于企业应用而言,多模态能力正在变得越来越重要:合同扫描件、PPT 截图、产品设计图、质检图片、客服聊天记录、监控画面、网页界面,都是实际业务中的常见输入。
如果模型只能处理文本,企业就必须先把这些材料转成文字,再交给模型分析;而原生多模态模型可以更直接地理解复杂信息结构,减少中间转换损耗。
更进一步,多模态能力与 Agent 能力结合后,模型就可能执行更复杂的任务:读取网页界面、理解报表截图、分析产品图、生成设计建议、检查文档版式,甚至在工具环境中完成跨应用操作。
这也是为什么 M3 的意义不能只看单一跑分。它试图补齐的是一个现代智能体所需的底层能力组合:长上下文负责记忆和材料承载,Coding 负责工具与工程执行,多模态负责感知,Agent 能力负责把它们组织成任务闭环。
五、国产大模型的竞争进入“可用性”阶段
这次 M3 发布,释放出一个明显信号:国产大模型正在从“追赶能力榜单”进入“追求真实可用性”。
过去,模型发布常常强调某项基准超过某个国际模型。但企业在真正选型时,关心的问题更具体:
- 能不能处理我完整的业务材料?
- 能不能稳定调用工具和系统?
- 能不能控制推理成本?
- 能不能在中文场景、本地部署、合规要求下工作?
- 能不能支撑 Agent 应用长期运行?
M3 的长上下文、稀疏注意力、编程 Agent 和多模态能力,恰好都指向这些问题。
当然,模型发布只是第一步。一个基础模型能否变成生产力,还取决于 API 稳定性、生态工具、开发者体验、企业部署方案、成本模型以及安全治理能力。国产模型要真正赢得企业市场,不仅要在跑分上好看,更要在真实场景中稳定、便宜、可控、可集成。
六、为什么说它是本周国产大模型最重磅发布?
把 M3 放在本周国产大模型动态中看,它的重磅不在于一句“超越 GPT-5.5”,而在于三点。
第一,它把竞争点放在真实任务能力上。SWE-Bench Pro 这类评测更接近工程任务,而不是单纯知识问答,这说明国产模型正在向高价值生产力场景推进。
第二,它强调长上下文和成本效率。1M Token 与 MSA 稀疏注意力的组合,意味着模型不仅要能读长材料,还要以更可持续的方式处理长任务。
第三,它面向 Agent 时代补齐能力栈。Coding、多模态、长上下文、工具调用和任务执行,正在成为下一代模型的必备能力,而 M3 的发布正是围绕这套能力栈展开。
因此,对企业管理者、开发者和 AI 产品团队来说,M3 值得关注的不是“有没有打败某个模型”,而是它代表了国产大模型的一个方向:从模型能力秀,转向智能体生产力。
结语:国产大模型下一战,是把能力变成可靠交付
MiniMax M3 的发布,让国产大模型再次站到聚光灯下。
在特定编程基准上超过 GPT-5.5 和 Gemini 3.1 Pro,是一个足够吸引眼球的信号;但更重要的是,M3 展示了长上下文、稀疏注意力、原生多模态和 Agent 能力的组合价值。
未来的大模型竞争,不会只是谁更会回答问题,而是谁更能进入真实工作流,读取完整上下文,理解复杂任务,调用工具执行,并以可控成本交付结果。
如果说过去的国产模型发布,更多是在证明“我们也能做强模型”,那么 M3 这类产品正在回答另一个问题:国产大模型能不能成为下一代智能体应用的可靠底座?
这,才是它真正值得关注的地方。
发布前可选标题
- MiniMax M3发布:在特定基准上超越GPT-5.5,本周国产大模型最值得关注的一次升级
- 1M上下文、MSA稀疏注意力、Agent能力增强:MiniMax M3重磅发布
- 国产大模型进入Agent时代:MiniMax M3为何值得关注?
- 不只看跑分:MiniMax M3把国产模型竞争推向真实任务能力
摘要建议
MiniMax 发布新一代基础模型 M3,支持 1M Token 长上下文,引入 MSA 稀疏注意力机制,并强化 Coding、Agent 和原生多模态能力。官方称其在 SWE-Bench Pro 等特定编程基准上超过 GPT-5.5 和 Gemini 3.1 Pro。相比单纯跑分,M3 更值得关注的是国产大模型正在从能力展示走向真实任务执行与智能体生产力。
参考来源
- MiniMax 官方博客:MiniMax M3 发布信息、模型能力与评测结果。
- MiniMax 官方模型文档:上下文窗口、MSA 稀疏注意力、Coding / Agent / Multimodal 能力说明。
- SWE-Bench Pro 等公开编程任务评测基准相关说明。
发布前风险提示
- “超越 GPT-5.5”建议保留为“在 SWE-Bench Pro 等特定基准上超过”,避免泛化为全面超越。
- GPT-5.5、Gemini 3.1 Pro 等模型名称与评测口径建议发布前再次核对 MiniMax 官方原文。
- 如正式发布需要更稳妥,可将主标题改为“MiniMax M3发布:国产大模型向Agent时代再进一步”。


")






