
📅 2026.05.27 | AITOP100 独家获悉🔑 "Something BIG is coming!" —— 工程负责人 Skyler Miao 社交平台重磅预告
一、从 M2 到 M3:锚定长上下文,架构级重构升级
MiniMax 作为国内最早深耕超长上下文技术的团队之一,M2 已实现 100 万 Token 上下文窗口,在长文档分析、超长对话、代码库理解等场景广泛落地。
即将登场的 M3 并非简单的参数堆叠或微调优化,而是一次 架构级重构。核心目标直指长上下文场景三大痛点:计算效率低、推理成本高、序列越长性能衰减越严重。在 GPT-4o、Claude 3.5 仍受限于传统 Transformer 瓶颈时,MiniMax 选择从底层注意力机制突破,技术野心可见一斑。
工具地址:Minimax官网
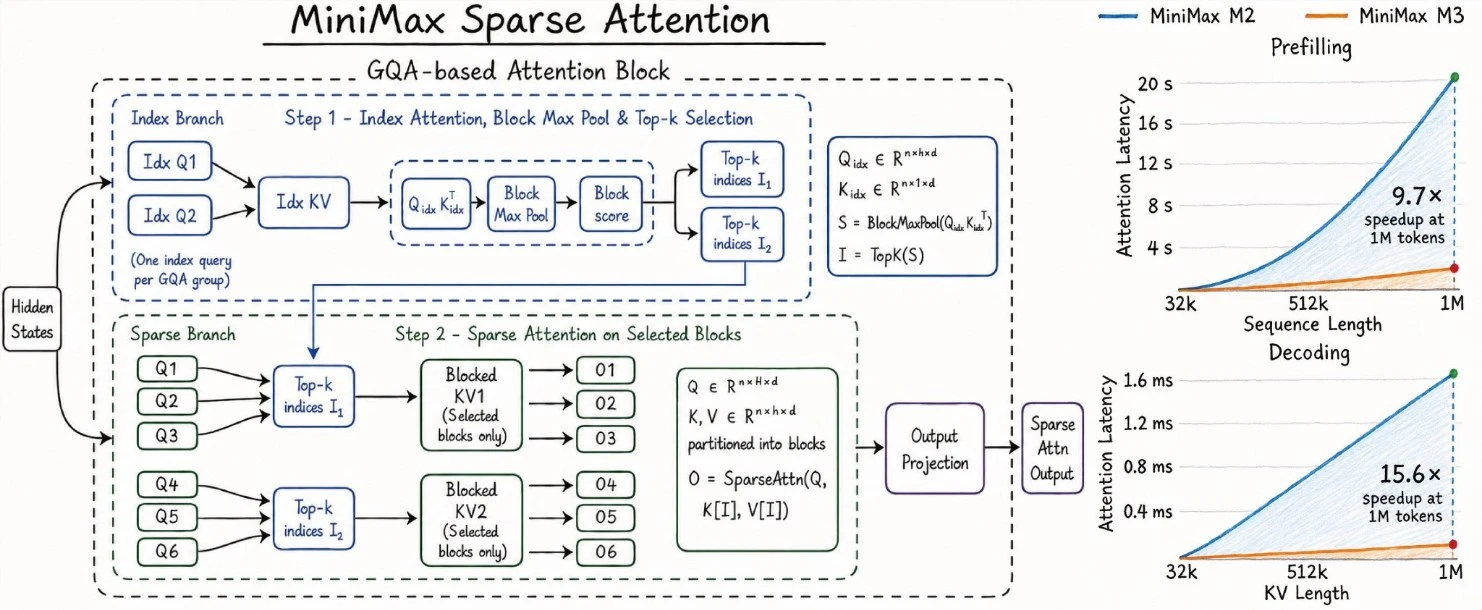
二、核心黑科技:稀疏注意力机制,破解百万 Token 计算死穴
❌ 传统架构的致命短板
标准 Transformer 注意力机制,处理序列长度为 n 时,计算复杂度为 O(n²)——序列每增长 10 倍,计算量暴涨 100 倍。百万 Token 级别(约 75 万字)下,单层注意力就需数十亿次操作,推理慢、成本高,这正是长上下文模型难以商用的核心原因。
✅ M3 稀疏注意力:Index + Sparse 双分支,精准"抓重点"
M3 创新采用 索引分支(Index Branch)+ 稀疏计算分支(Sparse Branch) 双分支设计:
- 索引分支:快速扫描整个上下文,筛选与当前任务强相关的关键 Token,过滤掉 90% 以上无效信息,避免全量计算
- 稀疏计算分支:仅针对索引分支筛选出的关键 Token 进行精准注意力计算,而非逐一关联
通俗来说,传统注意力像"逐字通读百万字文档",M3 则是"先快速定位核心段落,再精读关键内容"。百万 Token 场景计算量压缩至原来的 1/10 甚至更低,且不损失核心理解能力。
三、性能炸裂:M3 vs M2 实测对比
| 指标 | 提升幅度 | 实际意义 |
|---|---|---|
| Prefill(预填充) | 9.7 倍提速 | 百万级 Token 文档分钟级完成初始化 |
| Decoding(解码生成) | 15.6 倍提速 | 长文本续写、超长对话响应几乎无感知延迟 |
这组数据的实际价值:企业处理长文档,算力成本降低 80% 以上;个人用户超长对话,响应几乎零延迟。效率暴增的同时,上下文窗口仍保持百万 Token 级别,实现 "长窗口 + 高效率 + 低成本"三重突破。
四、行业影响:从"参数竞赛"到"效率革命",国产弯道超车
M3 的发布恰逢全球大模型关键转折点——此前行业一味比拼参数规模(万亿参数)、上下文长度(400 万 Token),却忽略落地效率与成本,多数超大模型仅能停留在实验室。
MiniMax M3 传递出明确信号:大模型竞争已从"堆参数、拼长度"的军备竞赛,转向 "架构创新、效率优先、实用落地" 的新赛道。
在海外大厂依赖传统 Transformer 架构难以突破效率瓶颈时,MiniMax 通过底层架构创新,在长上下文高效处理领域填补国内技术空白,为国产 AI 提供了绝佳的弯道超车机会。
未来,M3 的技术思路或推动更多大模型从"实验室走向生产线",在法律文书分析、金融研报解读、工业文档处理、超长代码库开发等场景规模化落地。
五、后续动态
- 发布时间:大概率未来 1-2 个月内亮相
- API 接口:极有可能同步开放企业级 API 供开发者与企业测试
- 开源计划:待定
AITOP100 将持续追踪 MiniMax M3 后续进展,第一时间带来技术拆解、性能实测与落地分析。
💡 一句话总结:
M3 不是更大的模型,而是更聪明的模型——用稀疏注意力把百万 Token 的计算成本打下来,让长文本 AI 真正走出实验室、走进生产线。
AITOP100-AI资讯频道将持续关注AI行业新闻资讯消息,带来最新AI内容讯息。
想了解AITOP100平台其它版块的内容,请点击下方超链接查看
AI创作大赛 | AI活动 | AI工具集 | AI资讯专区 | AI小说
AITOP100平台官方交流社群二维码:











