
在大模型推理规模持续扩张、长上下文与智能体任务成为主流的行业背景下,网络架构已成为制约AI算力效率的核心瓶颈。
2026年5月21日,智谱AI 联合 驭驯网络、清华大学 正式宣布,新一代 ZCube组网架构 已在 GLM‑5.1 coding 生产环境完成规模化落地——在 不更换GPU、不改动软件栈与应用逻辑 的前提下,实现:
🔼 推理吞吐提升 15%
💰 网络硬件成本削减 33%
⚡首Token时延降低 40.6%
该技术成果最早于2025年9月在网络领域国际顶会 ACM SIGCOMM 2025 公开发表,被评价为"显著改变行业对大模型网络架构的认知方式"。此次落地是ZCube架构首次从学术研究走向产业级部署,标志着智算基础设施正式进入 模型流量驱动、网络拓扑深度协同 的全新发展阶段。
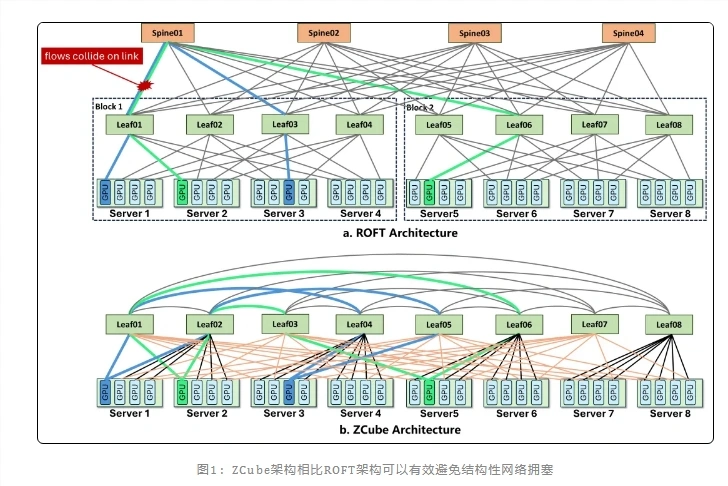
📌 一、行业痛点:传统网络架构成为大模型推理的性能瓶颈
随着大模型从对话交互向代码生成、长文本处理、智能体执行等复杂场景演进,KV Cache跨节点传输不对称、长上下文高频通信、Prefill‑Decode分离部署 成为常态。传统以 ROFT(Rail‑Optimized Fat‑Tree)为代表的多层Clos架构,采用 Spine‑Leaf 层级化堆叠设计,在万卡级集群中暴露出难以规避的结构性缺陷。
❌ 传统ROFT架构三大核心短板:
① 静态拓扑导致局部拥塞
固定链路分配易形成热点,出现"总带宽充裕、局部频繁阻塞"的矛盾现象,引发 PFC 反压与流量冲突,直接拉低整体推理效率。
② 硬件成本居高不下
多层交换机与光模块冗余配置,大幅提升数据中心资本支出,规模越大成本浪费越明显。
③ 扩展能力受限
层级化设计在超大规模集群中链路复杂度指数级上升,难以高效支持数万张GPU的线性扩展。
这些问题直接导致 GPU算力无法充分释放、推理时延波动大、硬件投入产出比偏低,成为制约大模型商业化落地的关键障碍。
📌 二、ZCube架构核心创新:扁平化拓扑从根源消除拥塞
ZCube架构彻底打破传统Clos架构的层级化思维,以 完全扁平化二部图互联 为核心,重构大模型推理集群的网络通信体系,实现 流量无阻塞、硬件极简、扩展无上限 三大技术突破。
🧱 1. 核心设计原理
🔸 取消Spine层交换机
摒弃多层堆叠,采用两组Leaf交换机直接构建扁平网络,大幅减少转发层级与硬件数量。
🔸 二部图最优路径
确保任意GPU之间存在 独享最短路径,从拓扑结构上杜绝流量冲突,实现全局负载均衡。
🔸 双端口网卡混合接入
结合单轨/多轨混合接入机制,适配大模型推理的非对称流量特征,提升链路利用率。
🔸 智能路由策略
基于模型通信模式动态调度,保障长上下文、KV Cache同步等关键任务的低时延传输。
📊 2. ZCube vs 传统ROFT架构关键对比
| 对比维度 | 传统ROFT架构 | ZCube架构 | 核心优势 |
|---|---|---|---|
| 网络拓扑 | Spine‑Leaf多层堆叠 | 完全扁平化二部图 | 无层级转发,降低时延 |
| 流量调度 | 静态分配,易拥塞 | 动态最优路径,无冲突 | 全局负载均衡,消除热点 |
| 硬件组成 | 需多层交换机+光模块 | 取消Spine层,硬件减半 | 成本降低33% |
| 扩展能力 | 千卡级瓶颈明显 | 支持数十万GPU线性扩展 | 适配超大规模集群 |
| 推理性能 | 易受反压影响,吞吐波动 | 稳定高吞吐,低时延 | 吞吐+15%,时延‑40.6% |

📌 三、生产环境实测数据:性能与成本双丰收
ZCube架构已在智谱 GLM‑5.1 coding 线上 千卡生产集群 稳定运行超两周,所有指标均通过严苛业务验证:
🔼 推理吞吐
GPU平均推理吞吐提升 15%,同等硬件条件下每秒可多响应15%的API请求,显著提升并发承载能力。
⚡ 响应时延
首Token时延(TTFT P99)降低 40.6%,大幅减少用户等待时间,高峰时段服务稳定性显著增强。
💰 硬件成本
交换机与光模块资本支出减少 33%,硬件投入直接削减三分之一,大规模部署经济效益突出。
🔄 兼容性
GPU、软件栈、应用 完全不变,无需代码改造即可平滑升级,保护现有算力资产,降低迁移风险。
实测结果证明,ZCube架构通过 网络拓扑与大模型通信特征深度耦合,实现了 不增硬件、不降性能、大幅降本 的产业级目标,为MaaS服务商提供了可复制的优化方案。
📌 四、工程落地突破:自动化部署保障平稳升级
超大规模网络架构改造面临 布线复杂、路由策略重构、业务零中断 等多重挑战。驭驯网络团队依托自主研发的 自动化控制与校验工具链,完成三大关键工程突破:
🔧 自动化布线规划
快速生成最优物理连接方案,缩短部署周期,降低人工误差。
🔀 路由策略一键切换
平滑替换原有网络规则,业务无感知升级,避免服务中断。
📡 全链路实时监控
对流量、带宽、时延等指标持续校验,确保集群稳定运行。
此次落地验证了ZCube架构的 工程可行性与大规模兼容性,可快速推广至各类智算中心与大模型推理集群。
📌 五、行业价值:引领智算基础设施新范式
ZCube架构的成功落地,不仅是智谱AI在AI基础设施领域的重要突破,更对全球大模型产业产生深远影响:
✅ 算力效率革命
通过网络架构创新释放存量硬件潜能,同等算力产出提升15%,推动AI算力从拼硬件向拼架构转型。
✅ 成本结构优化
网络硬件成本直降三分之一,大幅降低大模型推理与MaaS服务的准入门槛,加速普惠AI落地。
✅ 技术路线引领
证明 网络拓扑、通信库、调度策略深度协同 是下一代智算中心的核心方向,为行业提供全新技术路径。
✅ 国际竞争力提升
中国团队原创网络架构率先实现产业落地,在超大规模AI基础设施领域达到国际领先水平。
📌 六、总结
ZCube架构以 扁平化无拥塞拓扑 为核心,在 GLM‑5.1 coding 生产环境中验证了 推理吞吐+15%、硬件成本‑33%、首Token时延‑40.6% 的卓越性能,破解了传统网络架构制约大模型效率的行业难题。
作为首个从顶会研究走向规模化落地的大模型专用网络架构,ZCube重新定义了智算基础设施的设计理念,推动行业从 通用互联 迈向 模型流量驱动的系统协同。
未来,随着ZCube在更多大模型场景与智算中心的普及,将持续提升AI算力效率、降低产业成本,为大模型技术的深度商业化提供坚实底层支撑。
AITOP100-AI资讯频道将持续关注AI行业新闻资讯消息,带来最新AI内容讯息。
想了解AITOP100平台其它版块的内容,请点击下方超链接查看
AI创作大赛 | AI活动 | AI工具集 | AI资讯专区 | AI小说
AITOP100平台官方交流社群二维码:











