
在语义表征领域,打破"英语中心主义"的壁垒正成为大模型进化的新战场。3月26日,蚂蚁集团CodeFuse团队联合上海交通大学正式发布了F2LLM-v2系列Embedding模型。该系列模型不仅在权威评测中展现了统治级的表现,更以全开源的姿态,为全球开发者提供了一套兼顾高性能与极致效率的语义表征方案。

实力霸榜:MTEB评测横扫11项SOTA
在衡量Embedding模型最权威的MTEB榜单中,F2LLM-v2展现了全方位的领先优势。该模型在德语、法语、日语以及代码检索等11个语种和领域榜单中位列第一。即便是家族中的轻量级成员,在同尺寸下也多次击败了业界知名大模型。评测任务涵盖医疗问答、代码检索等430个细分场景,实现了无死角覆盖。
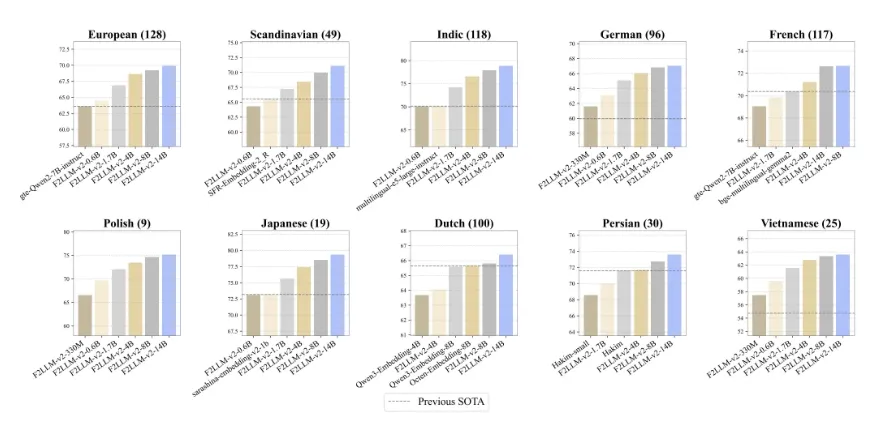
全能理解:精通282种自然语言与40+种代码
F2LLM-v2的强悍源于其极其包容的训练底座。该模型特别加强了对中低资源语言(如北欧语系、东南亚语系等)的支持,真正实现了全球化覆盖。同时,它深入理解Python、Java、Go等40多种编程语言,是RAG(检索增强生成)和代码助手开发者的理想选择。依托6000万经过严苛清洗的公开资源样本,确保了模型知识的纯粹性与广泛性。
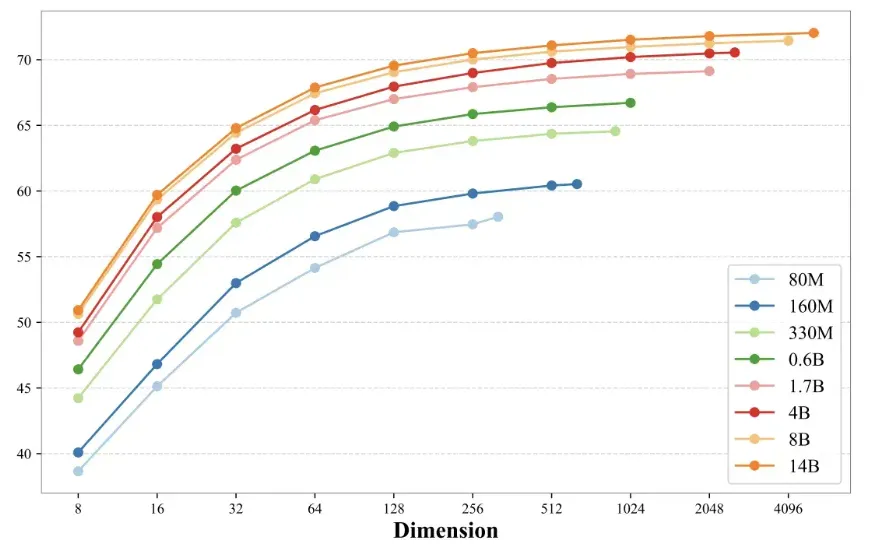
极致高效:从80M到14B的全尺寸家族
为了适配从移动端到云端的全场景需求,CodeFuse团队打造了完整的模型矩阵。80M-330M的小模型采用"模型裁剪"与"知识蒸馏"技术,可在移动设备上流畅运行。更值得关注的是,该系列支持**"套娃"黑科技**——动态维度调整,用户可以在8维到全维度之间自由切换,在推理速度与存储成本之间找到完美平衡。
纯粹开源:透明度定义社区标准
不同于许多"黑盒"模型,F2LLM-v2坚持走完全开源路线。所有尺寸的模型权重均已开放下载,公布完整技术报告揭秘训练全过程,并释放全部代码与检查点,鼓励全球研究者在此基础上进行二次开发。
作为CodeFuse开源系列的又一力作,F2LLM-v2的发布不仅提升了多语言RAG的准确率,更为全球开发者提供了一个公平、透明且高性能的技术底座。在AI席卷全球的今天,听懂世界,从每一个精准的Embedding开始。
AITOP100-AI资讯频道将持续关注AI行业新闻资讯消息,带来最新AI内容讯息。
想了解AITOP100平台其它版块的内容,请点击下方超链接查看
AI创作大赛 | AI活动 | AI工具集 | AI资讯专区 | AI小说
AITOP100平台官方交流社群二维码:




")






