
Liquid AI 今日正式发布 LFM2.5-1.2B-Thinking,这是一款专为完全在 本地端(On-Device) 运行而设计的推理模型。该模型实现了惊人的轻量化突破,仅需 900 MB 内存 即可在普通智能手机上流畅运行。作为一款以 “简洁推理” 为训练目标的新一代模型,它能够在输出最终答案前生成 内部思维轨迹,将以往需要数据中心级算力才能实现的复杂推理能力,成功迁移至用户掌中的移动终端。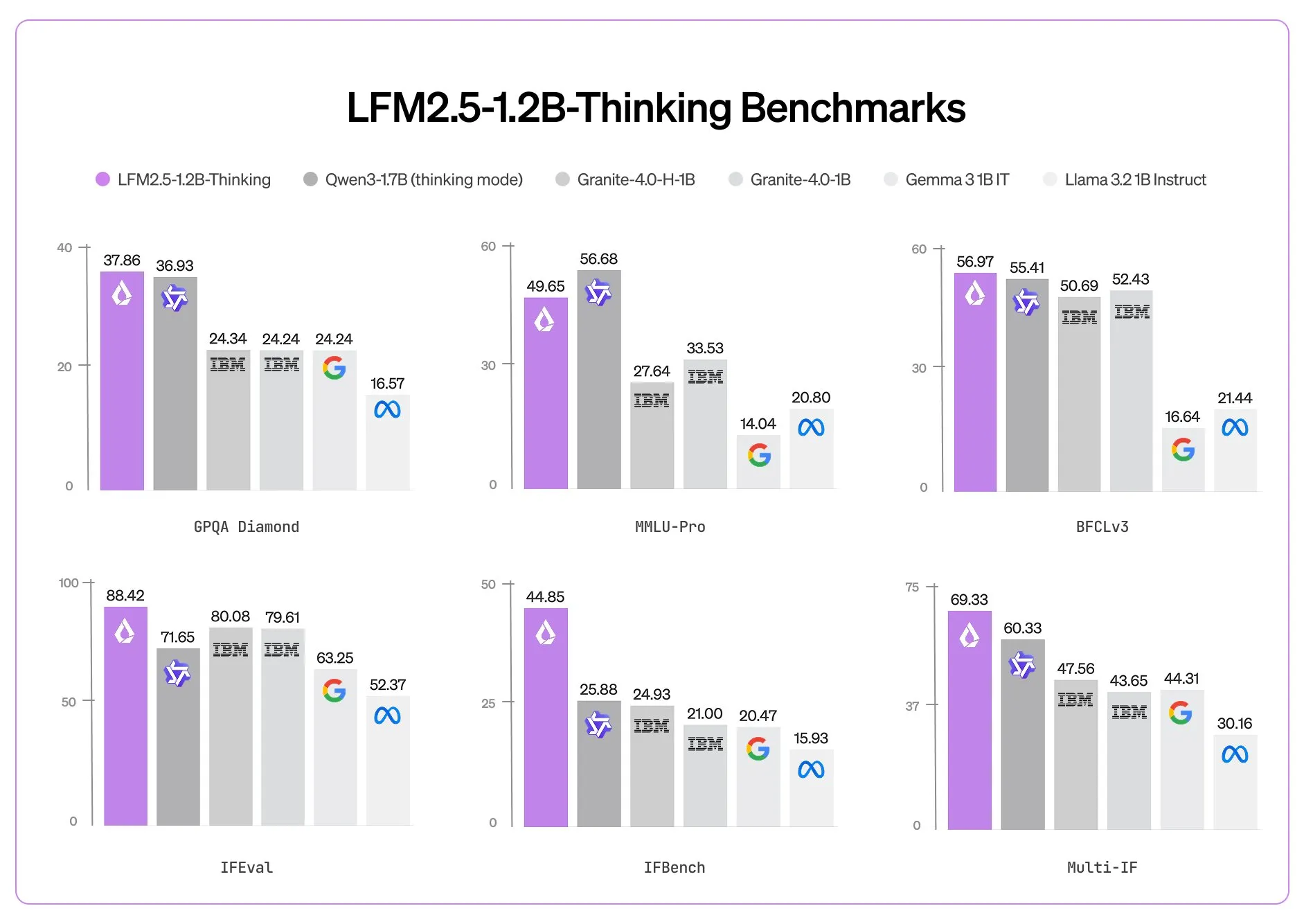
模型核心能力与技术特性
LFM2.5-1.2B-Thinking 不仅仅是参数量的压缩,更是在训练方法论上的革新。其核心技术特性集中体现在以下几个维度:
关键技术指标
- 简洁推理(Concise Reasoning): 模型被训练以最直接、高效的路径解决问题,减少冗余计算。
- 内部思维轨迹: 能够先生成隐式的思考步骤(Internal Thinking Traces),再输出最终答案,显著提升逻辑一致性。
- 边缘规模延迟(Edge-Scale Latency): 专为低延迟场景优化,确保在移动设备上的响应速度满足实时交互需求。
- 多领域专精: 在工具使用(Tool Use)、数学计算(Math)以及复杂指令跟随(Instruction Following)方面表现优异。
工作流:从 “直觉” 到 “深思” 的进化
传统的端侧小模型往往为了速度而牺牲深度,倾向于直接生成答案。而 LFM2.5-1.2B-Thinking 引入了类似 “系统 2”(System 2)的慢思考机制。通过在输出结果前构建 内部思维轨迹,模型能够自我校正逻辑谬误,从而大幅提升答案的稳定性和可解释性。
在 On-Device 的严苛资源约束下实现这种 “链式/树式” 思维是一项巨大的工程挑战。Liquid AI 通过优化推理路径,使得这种复杂的思维过程不再依赖云端巨型算力,而是能够在本地芯片的算力预算内完成,真正实现了 “把大脑装进口袋”。
性能门槛:900MB 的端侧革命
“两年前需要数据中心才能做到的事,现在只需要一部手机。”900 MB 的内存占用意味着目前市面上绝大多数智能手机、甚至部分高端 IoT 设备都能轻松承载该模型。
- 零隐私风险: 数据无需上传云端,完全本地处理。
- 离线可用: 在弱网或无网环境(如飞机、偏远地区)仍能全功能工作。
- 极致优化: 结合权重压缩与线性注意力(Linear Attention)等技术,最大化硬件利用率。
应用场景与未来展望
LFM2.5-1.2B-Thinking 的发布为端侧 AI 打开了新的应用大门,尤其是在对隐私和实时性要求极高的场景中:
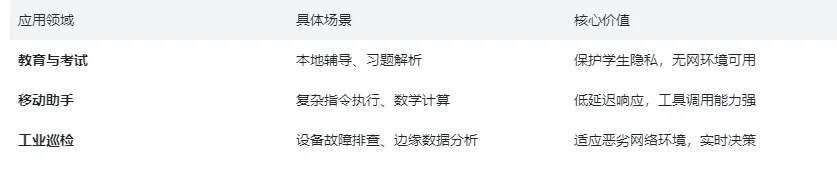
注意事项:尽管表现惊人,但在处理超长上下文或极端复杂的逻辑推理时,受限于模型尺寸和端侧内存,仍需合理设定预期,做好资源匹配。
LFM2.5-1.2B-Thinking 成功将 “本地端推理 + 简洁思考 + 工具能力” 三者合而为一,标志着端侧智能进入了一个 “会思考” 的新阶段。它证明了高效能不再是巨型模型的专利,小模型通过优秀的算法设计同样能迸发大智慧。建议开发者与行业用户密切关注其后续发布的基准数据与开放测试入口。
AITOP100-AI资讯频道将持续关注AI行业新闻资讯消息,带来最新AI内容讯息。
想了解AITOP100平台其它版块的内容,请点击下方超链接查看
AI创作大赛 | AI活动 | AI工具集 | AI资讯专区 | AI小说
AITOP100平台官方交流社群二维码:











