
在2025年的AI图像生成江湖里,又杀出一匹黑马!阿里通义实验室推出的开源神器Qwen-Image-i2L正式上线,直接把“个性化风格迁移”的门槛打到了地板价。以前想让AI学个新画风?得准备20多张图、租GPU集群,现在呢?一张图就能搞定,这不就是“AI艺术平民化”的里程碑吗?
模型地址: https://modelscope.cn/models/DiffSynth-Studio/Qwen-Image-i2L/summary
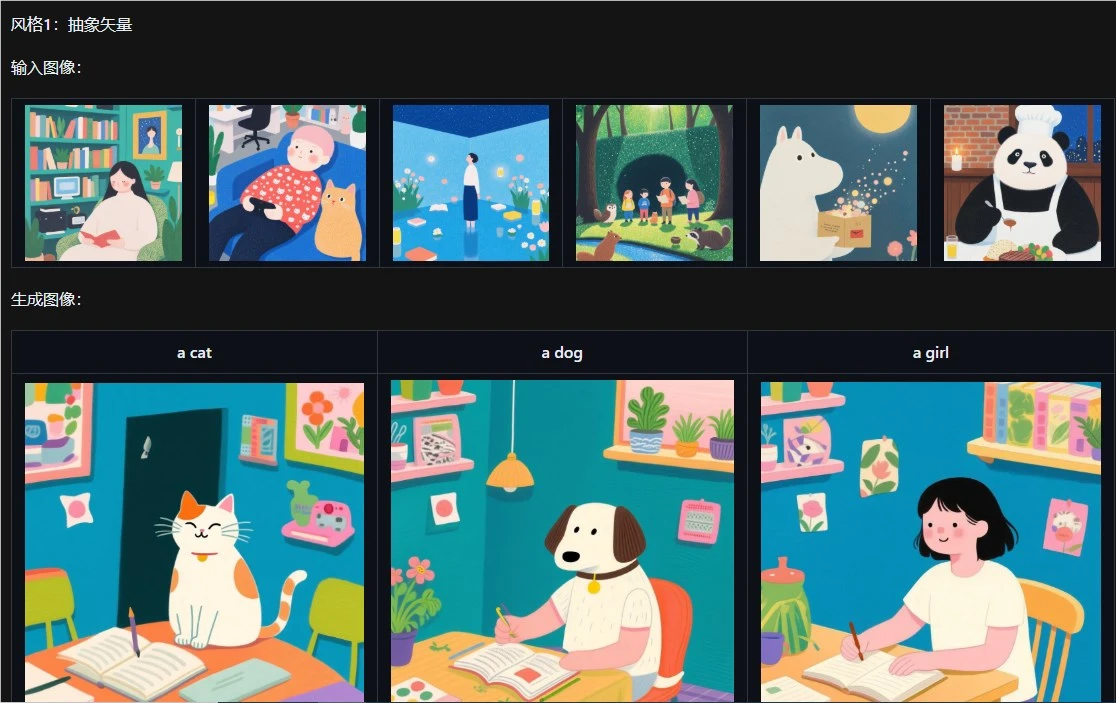
核心创新:单图变LoRA,创作像“拼乐高”一样简单
Qwen-Image-i2L的杀手锏,是它的图像分解机制。想象一下,你拍了一张夕阳下的海边照片,系统会像拆盲盒一样,把画面拆成“柔和的暖色调、流动的浪花纹理、远处的帆船构图”这些可学习的“零件”。这些零件被压缩成轻量级LoRA模块,体积小到只有几GB,却能精准捕捉原图的精髓。
对比传统训练流程,这简直是“降维打击”:以前要20+张图+GPU集群,现在一张图+普通电脑就能搞定;以前调参数调到手抽筋,现在“一键学习”直接生成模块。生成的LoRA还能无缝塞进Stable Diffusion等模型里,想生成多少张同风格的新图,全看你的创意够不够!
更绝的是,社区反馈显示,这功能特别适合“快速试错”。比如你想试试把梵高的《星月夜》风格用在现代建筑上,或者把动漫角色的画风迁移到真人照片里,以前得折腾半天,现在几分钟就能看到效果。开源后,开发者们已经开始把它用在产品设计和数字艺术里,说不定你下次看到的广告海报,就是用它生成的!

四款模型变体,总有一款适合你
Qwen-Image-i2L可不是“一招鲜吃遍天”,它准备了四款“定制款”模型,针对不同场景优化:
- 风格模式(2.4B参数):专攻“纯美学”,比如把水彩画的笔触迁移到新图上,或者让照片秒变油画质感。
- 粗粒度模式(7.9B参数):内容+风格一起抓,适合快速重构场景,比如把城市街景变成赛博朋克风,或者把自然风景变成童话世界。
- 精细模式(7.6B参数):支持1024x1024高分辨率,细节控必备!常和粗粒度模式搭配,让纹理和边缘更清晰,比如生成超逼真的动物毛发或建筑砖块。
- 偏见模式(30M参数):企业级应用神器,确保输出和Qwen-Image原生风格一致,避免品牌“跑偏”,比如统一公司所有宣传图的色调和风格。
这四款模型都基于Apache2.0许可开源,在Hugging Face或ModelScope平台免费下载。测试显示,它在复杂文本渲染和语义编辑上,比多数开源工具强,甚至能和闭源模型掰掰手腕!
技术底蕴深厚,但也要小心“翻车”
Qwen-Image-i2L的底气,来自它的“老大哥”Qwen-Image(20B参数MMDiT架构)。这个基础模型已经在GenEval、DPG等基准测试里拿过冠军,尤其是中英双语文本渲染,直接领先行业。再加上FlowMatchEuler调度器的加持,生成一张图只要几秒,速度快到飞起!
不过,社区讨论也指出了它的“软肋”:从单张2D图提炼3D逻辑,就像“用一张照片猜整个房间的布局”,容易“想当然”。比如你传了一张“猫在沙发上”的照片,生成的图可能在其他角度“猫悬空”或者“沙发变形”。开发者建议,可以结合多步蒸馏或加点辅助数据集,让输出更稳定。
未来发展:AI创作进入“即时定制”时代
Qwen-Image-i2L的出现,标志着AI图像工具从“通用生成”升级至“即时定制”。对创作者来说,它像是个“风格魔法棒”,想变什么画风就变什么;对电商、游戏、影视行业来说,它则是“效率加速器”,能快速生成符合品牌调性的素材,节省大量时间和成本。
更让人期待的是,随着生态扩展,未来可能会出现更多“一键创新”应用,比如“一键生成漫画分镜”“一键设计游戏角色”,让AI创作更普惠、更有趣。说不定哪天,你也能用它做出自己的“数字艺术品”,在社交平台上一鸣惊人!
相关冷知识:你知道吗?Qwen-Image-i2L的图像分解机制,灵感其实来自人类大脑的“视觉处理模式”——我们看一张图时,也会自动拆解成颜色、形状、纹理等元素。这种“仿生设计”,让它的学习效率更高,也更接近人类的创作逻辑。
想了解AITOP100平台其它版块的内容,请点击下方超链接查看
AI创作大赛 | AI活动 | AI工具集 | AI资讯专区
AITOP100平台官方交流社群二维码:



")






