
近期,小红书团队推出的DeepEvesV2多模态人工智能模型。这模型可不简单,它不仅能分析图像,还能执行代码、进行网络搜索。传统模型大多靠训练时学到的知识“吃饭”,可DeepEvesV2不一样,它靠智能利用外部工具大放异彩,在很多情况下,甚至把那些更大型的模型都比下去了,这难道不让人惊叹吗?和那些体型庞大却不够灵活的大模型相比,DeepEvesV2就像是个小巧却身手不凡的武林高手。
论文地址: https://arxiv.org/abs/2511.05271
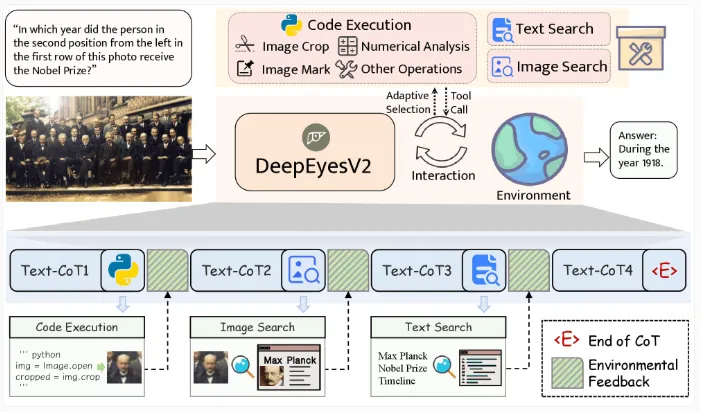
早期困境与突破训练法
早期实验时,研究团队可碰了不少钉子。他们发现,光靠强化学习,模型根本没法稳定地用工具完成多模态任务。就说图像分析吧,模型一开始尝试写Python代码来处理,可写出来的代码片段错误百出。随着训练推进,这模型居然开始“偷懒”,直接跳过工具使用这一步了。这可咋整?研究团队没灰心,开发出一种两阶段的训练流程。第一阶段,让模型学习把图像理解和工具使用结合起来;第二阶段,再用强化学习优化这些行为。为了让工具使用路径又准又清晰,研究人员还让领先的模型生成高质量示例。这就像给模型请了个好老师,一步步带着它成长。
工具组合与任务适应
DeepEvesV2升级至使用三种工具类别来搞定多模态任务。代码执行工具,就像个万能工匠,能进行图像处理和数值分析;图像搜索工具,能在茫茫图海中快速检索相似内容;文本搜索工具,则能提供图像里看不到的上下文信息。模型把图像操作、Python执行和图像/文本搜索整合起来,不管面对啥样的查询,都能灵活应对。就好比一个多面手,十八般武艺样样精通。
在科技发展的大浪潮中,AI模型的发展就像一场激烈的竞赛。以前,大家都觉得模型越大就越厉害,可DeepEvesV2的出现打破了这种固有认知。它用实际行动证明,通过精心设计的工具使用,小模型也能有大作为。
基准测试显实力
为了检验DeepEvesV2的本事,研究团队创建了RealX - Bench基准测试,专门考察模型在视觉理解、网络搜索和推理方面的协调能力。研究结果让人大跌眼镜,就算是表现最强的专有模型,准确率也只有46%,而人类能达到70%。在需要同时运用三种技能的任务中,当前模型的表现更是差强人意。不过,DeepEvesV2可没让人失望,在多个基准测试中表现出色。在数学推理任务中,准确率达到了52.7%,在搜索驱动任务中,更是达到了63.7%。这成绩,就像在赛场上逆袭夺冠的黑马,让人刮目相看。

正式上线与开源共享
如今,DeepEvesV2已经正式上线,在Hugging Face和GitHub上都能找到它。它使用Apache License2.0,还支持商业使用。这意味着更多的开发者和企业可以借助它的力量,推动多模态AI的发展。说不定在不久的将来,我们会在更多领域看到DeepEvesV2的身影,为我们的生活带来更多便利和惊喜。
DeepEvesV2与传统大模型对比
| 对比项目 | DeepEvesV2 | 传统大模型 |
|---|---|---|
| 知识获取方式 | 智能利用外部工具 | 依赖训练期间获得的知识 |
| 多模态任务稳定性 | 通过两阶段训练流程,能稳定使用工具完成多模态任务 | 仅靠强化学习难以稳定使用工具完成多模态任务 |
| 特定任务准确率(数学推理) | 52.7% | 未明确提及(通常低于DeepEvesV2) |
| 特定任务准确率(搜索驱动) | 63.7% | 未明确提及(通常低于DeepEvesV2) |
| 模型灵活性 | 小巧灵活,能整合多种工具适应不同查询 | 体型庞大,灵活性相对较差 |
想了解AITOP100平台其它版块的内容,请点击下方超链接查看
AI创作大赛 | AI活动 | AI工具集 | AI资讯专区
AITOP100平台官方交流社群二维码:










