
DeepSeek NSA:AI领域长文本处理的重大突破
人工智能领域迎来一项重要进展,DeepSeek 团队近日发布了创新性的研究成果——NSA(Native Sparse Attention)稀疏注意力机制。该技术旨在加速长上下文的训练和推理过程,并针对现代硬件环境进行了深度优化,从而实现训练和推理效率的显著提升。
NSA 技术的核心优势
NSA 技术的推出,为人工智能模型的训练带来了革命性的变化。其核心优势体现在以下几个方面:
- 显著提升推理速度:通过针对现代计算硬件的优化设计,NSA 大幅提升了推理速度。
- 有效降低预训练成本:在速度提升的同时,NSA 有效降低了预训练所需的资源和时间成本。
- 保持高水平的模型性能:NSA 在提升速度和降低成本的同时,确保模型在各种任务中的表现不受影响,维持了高水平的模型性能。
NSA 的分层稀疏策略
DeepSeek 团队在 NSA 研究中采用了一种独特的分层稀疏策略,将注意力机制分解为三个关键分支:
- 压缩:对输入信息进行有效压缩,减少计算量。
- 选择:智能选择重要的信息片段,聚焦关键信息。
- 滑动窗口:利用滑动窗口机制捕捉局部上下文信息。
这种分层设计使模型能够同时捕捉全局上下文和局部细节,从而显著提高模型对长文本的处理能力。此外,NSA 在内存访问和计算调度方面的优化,使得长上下文训练的计算延迟和资源消耗得以大幅降低。
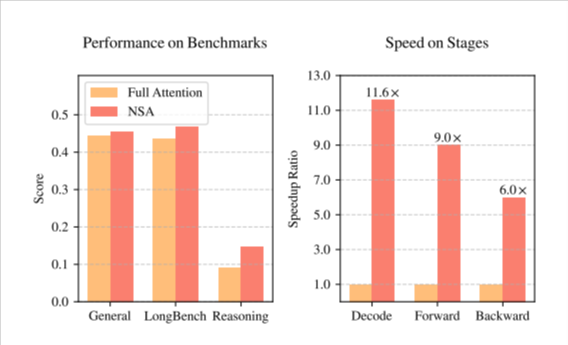
NSA 在基准测试中的卓越表现
在一系列通用基准测试中,NSA 展示了其卓越的性能。尤其是在长上下文任务和基于指令的推理方面,NSA 的表现甚至可以与完全注意力模型相媲美,在某些情况下甚至更胜一筹。这一技术的发布,标志着 AI 训练和推理技术领域的又一次重大飞跃,将为未来的人工智能发展注入新的动力。
NSA 论文 可以在arxiv上进行查阅学习。
NSA 的关键要点总结 NSA 显著提升了长上下文训练和推理的速度,并有效降低了预训练成本。 采用分层稀疏策略,将注意力机制分为压缩、选择和滑动窗口,增强了模型对长文本的处理能力。 在多项基准测试中,NSA 表现优异,在部分情况下甚至超越了传统的完全注意力模型。
目前由于访问人数较多导致DeepSeek服务器超负荷,大家可以从另外2个渠道去使用,不会卡:
渠道一:硅基流动(SiliconFlow):AI人工智能云服务平台
DeepSeek官网下载: 【点击登录】









