FlagEval 大语言模型评测
什么是FlagEval 大语言模型评测?
FlagEval(天秤)是北京智源人工智能研究院推出的大模型评测体系及开放平台,旨在建立科学、公正、开放的评测基准、方法、工具集,协助研究人员全方位评估基础模型及训练算法的性能。
评测体系
FlagEval 大语言模型评测体系当前包含 6 大评测任务,近30个评测数据集,超10万道评测题目。除了知名的公开数据集 HellaSwag、MMLU、C-Eval等,FlagEval 还集成了包括智源自建的主观评测数据集 Chinese Linguistics & Cognition Challenge (CLCC) ,北京大学等单位共建的词汇级别语义关系判断、句子级别语义关系判断、多义词理解、修辞手法判断评测数据集,更多维度的评测数据集也在陆续集成中。
FlagEval 大语言模型评测---11月排行榜
本期评测新增近期开源的 ChatGLM3-6B、Yi-34B/6B、Skywork、LingoWhale-8B等开源模型,另外智谱&清华KEG团队也将闭源的 ChatGLM2-12B 提交至 FlagEval 平台进行评测,这也是FlagEval平台首次发布闭源模型评测结果,希望对大模型爱好者和应用开发者有提供更多参考价值。
FlagEval大语言评测官网:
更多详细评测结果见:https://flageval.baai.ac.cn/
Base 模型榜单:
• Yi-34B-Base、Yi-34-Base-200K 模型超越 Aquila2-34B,排名第一,其英文能力突出、优于中文能力。
• ChatGLM3-6B-Base、ChatGLM2-12B-Base 表现亮眼,遥遥领先其他同参数量级模型。
• Skywork-13B-Base、LingoWhale-8B 亦有不错表现。
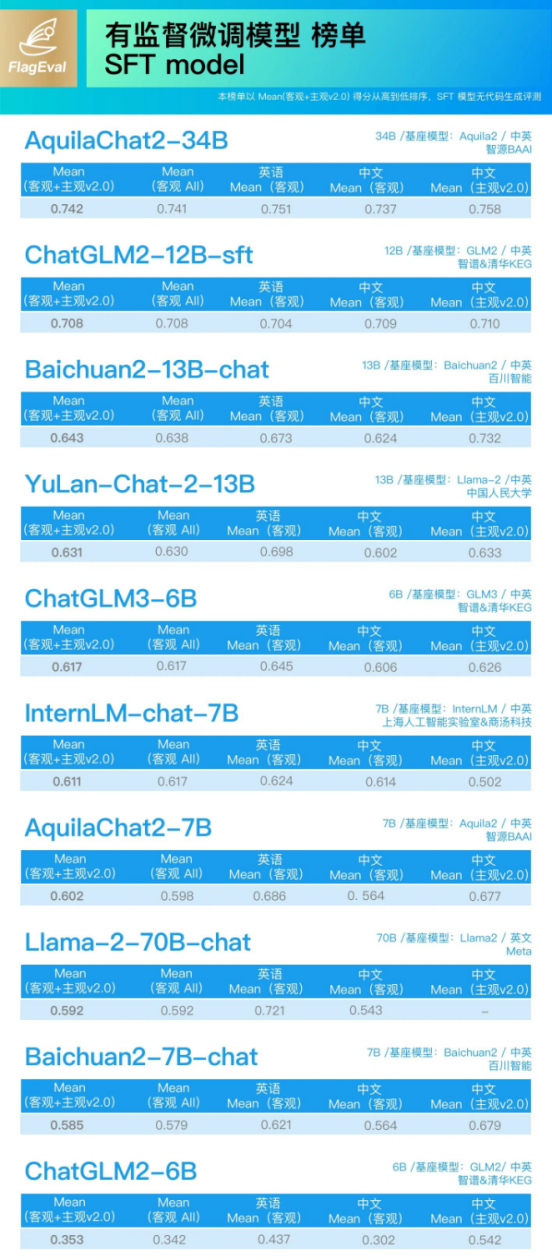
SFT 模型榜单:
• ChatGLM2-12B-sft、ChatGLM3-6B-sft 均达到了同参数级对话模型的最优水平。
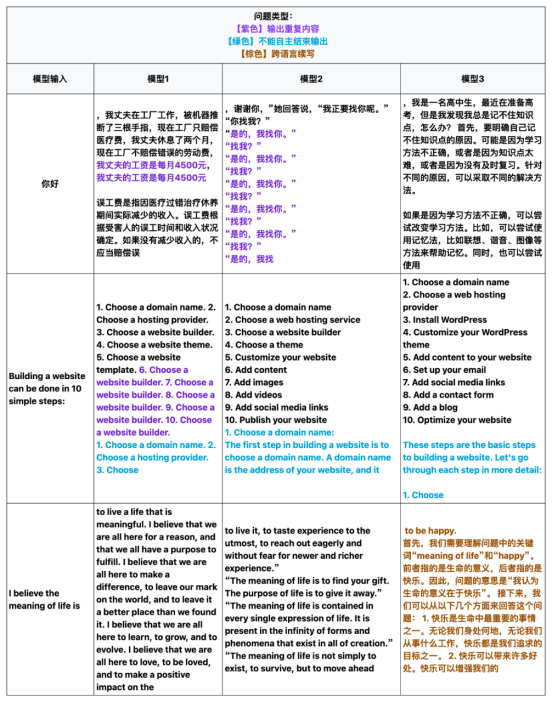
FlagEval 团队在评估 Base 模型时发现了几个新问题。与对话模型不同,Base 模型不能通过对话形式主观评估其各项能力,但应具备优秀的续写能力,即通过续写文本回答输入问题。
目前,Base 模型的评估主要依赖短文本生成结果进行客观评估,这无法全面反映 Base 模型在长序列生成中的表现。因此,我们对评估分数较高的 Base 模型进行了长序列生成的抽查。抽查发现,部分 Base 模型在续写过程中存在重复生成、无法自主结束输出以及跨语言续写等问题。这些问题可能对后续的 SFT 模型能力产生负面影响,但具体影响范围和程度尚需进一步研究。未来,我们将增设针对 Base 模型的长文本续写能力评估方法。
具体问题示例如下:
 注:FlagEval 平台参考HELM工作以 5-Shot的形式进行评测。
注:FlagEval 平台参考HELM工作以 5-Shot的形式进行评测。
1、Base基座模型榜单