
腾讯做了个"3D世界生成器",游戏厂商和具身智能都能用
3D内容的制作,长期以来都是个高门槛的活。
做一个游戏关卡,需要3D建模师一点点搭场景、布物件、调试光照。做具身智能的训练环境,需要把真实空间数字孪生出来。这两件事以前都得靠专业人员手动完成,费时费力。
腾讯混元团队今天开源的混元3D世界模型2.0,想做的是把这个过程自动化。
- 工具地址:腾讯混元3D官网
- 项目地址::https://github.com/Tencent-Hunyuan/HY-World-2.0
- 技术报告: https://3d-models.hunyuan.tencent.com/world/world2_0/HY_World_2_0.pdf
从"捏物体"到"造世界"
上一代3D生成模型,大多数做的是"单个物体"——你给它一句话,它给你生成一个椅子、一辆车、一棵树。但你想生成一个完整的、可探索的3D场景?对不起,做不了。
HY-World2.0的核心升级,就是把能力从**“生成物体"扩展到"生成世界”**。它不只能生成单独的3D模型,还能把整个3D空间——包括人、物、景——一起生成出来。
具体来说,它支持三种输入模态:文字、图片、视频。你输入一段文字描述"一个阳光明媚的城市街道",它生成的是一整个可探索的3D场景,不是一棵树或者一盏路灯。
而且生成的是可交互、可编辑的资产。你可以在生成结果上继续调整、加东西、改布局,不是一个"定死了"的静态文件。
技术上它怎么做到的?
聊聊几个核心升级:
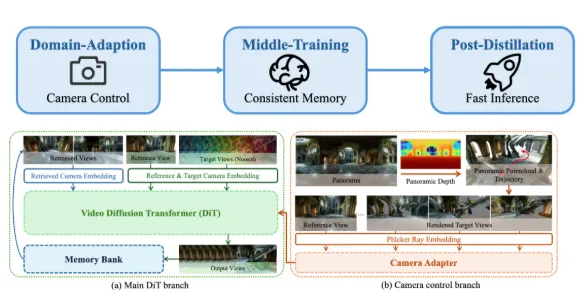
1.HY-Pano-2.0:360度全景映射
它用端到端隐式学习方案,能在没有相机参数的情况下完成360度全景映射。翻译成人话就是:你不需要提供专业的拍摄参数,它自己能从输入内容里推算出空间结构。这个设计降低了使用门槛,让普通用户也能生成高质量的全景3D内容。
2.空间Agent:智能规划漫游轨迹
腾讯自研的空间Agent技术,结合了视觉语言模型(VLM)和navmesh表征。简单说,就是它不只能生成静态场景,还能理解场景的空间结构,规划出合理的漫游路径。生成出来的3D场景不只是摆在那里的静态资产,而是有"路"的,你可以让角色在里面走。
3.WorldStereo:跨区域一致性
当你往一个已有场景里加入新生成的区域,它能确保新区域和原有区域在几何和视觉上保持一致。不会出现"新房间和走廊尺寸对不上"或者"光照方向不一致"这种尴尬的问题。
4.WorldMirror2.0:真实场景复刻
它还能复刻真实场景,一次性预测密集点云和相机参数,实现高精度的数字孪生构建。这个能力对于具身智能训练来说很有价值——你可以在数字孪生环境里训练机器人,训练完再放到真实环境里验证。
它比竞品强在哪?
官方专门提到,相比谷歌的Genie3等主流模型,混元2.0的关键突破在于生成的资产具备真实物理碰撞属性,支持角色模式自由探索。
这很重要。Genie3这类模型生成的是偏"视觉展示"型的3D内容,生成出来的东西更像"摆在橱窗里的模型",物理属性不够真实,不能直接拿去做游戏关卡。混元2.0生成的资产是"可以直接用的"——放到游戏引擎里就能用,有碰撞、有路径、可探索。
加上它支持Mesh、3DGS、点云等多种格式导出,可以直接对接Unity和UE这类主流游戏引擎。对于游戏开发团队来说,这意味着3D内容创作的第一步可以直接用AI完成,而不是从头手工建模。
意味着什么?
腾讯混元这步棋走的是个很实在的方向:把3D内容创作往实用化推。
"造世界"这个能力,对于游戏关卡原型制作、具身智能仿真环境构建来说,是真实需求。门槛降下来了,更多团队就能用上这个能力——不只是大厂能做3A游戏关卡,中小团队也能用AI辅助快速搭环境。
这大概就是腾讯混元这波开源的核心目标:把能力开放出去,让整个行业生态一起来用。
AITOP100-AI资讯频道将持续关注AI行业新闻资讯消息,带来最新AI内容讯息。
想了解AITOP100平台其它版块的内容,请点击下方超链接查看
AI创作大赛 | AI活动 | AI工具集 | AI资讯专区 | AI小说
AITOP100平台官方交流社群二维码:






![[AI漫剧城市沙龙·成都站]效能+精品抢跑AI漫剧下半场](https://aitop100app-1251510006.cos.ap-shanghai.myqcloud.com/public/2026/04/14/17/44/33/f0e57517-2778-4bab-94be-cbbffeeb43b1.png?imageMogr2/format/webp/thumbnail/480x/rquality/80 "[AI漫剧城市沙龙·成都站]效能+精品抢跑AI漫剧下半场")




