
一句话生成PPT还能主动揪Bug!OpenAI发布ChatGPT for PowerPoint插件
全球职场人的"PPT噩梦"或许即将终结。5月22日,OpenAI毫无征兆地在开发者生态中发布重磅炸弹:正式推出ChatGPT for PowerPoint插件(Beta版)。ChatGPT不再只是浏览器里陪你"纸上谈兵"的对话框,它已正式嵌入PowerPoint底层架构,成为你幻灯片创作过程中的"隐形合伙人"。
这次更新的三个核心看点很实在:零门槛全免费,无论是ChatGPT Plus付费会员还是普通免费账号,全球用户即刻起均可安装体验;全能助手,支持从零新建PPT、一键修改/润色页面,甚至能像专家一样"复盘"你的方案;安全可控,引入关键操作确认机制,拒绝"AI自作主张",确保每一处修改都尽在掌握。
实际使用场景有三个颠覆性变化。一是"无中生有":你只需输入指令,比如"帮我生成一份关于2026年度人工智能产业发展趋势的演示文稿,包含10页,风格要简洁专业",ChatGPT自动规划大纲、匹配布局并生成具备专业逻辑的幻灯片初稿。二是"润色医生":针对已有PPT页面,直接发出指令修改文案、调整配色,AI实时响应并直接在文档中执行修改。三是"隐形专家":ChatGPT能深入分析演示文稿,自动识别内容逻辑缺口,比如提示"你的市场调研部分缺乏竞争对手数据分析,可能导致方案缺乏说服力",甚至能预判汇报现场老板最可能问出的棘手问题。
安全设计上,OpenAI引入了"人在回路(Human-in-the-loop)“机制,对于涉及结构大改、重要文字增删等关键操作,插件会强制弹窗请求确认,只有在你点头之后,AI才会真正对文档进行"手术”。对于办公自动化产业而言,ChatGPT原生接入PowerPoint意味着底层逻辑已经发生了位移:未来的PPT制作,将不再是"人通过鼠标画图",而是"人作为总监,通过AI主动拆解大纲、填充数据、润色逻辑"。
工具地址:ChatGPT官网(海外网站需要科学上网)
Spotify联手环球音乐推出AI翻唱与混音:正版版权的"降维打击"来了
流媒体和音乐版权帝国终于对野蛮生长的AI音乐祭出了大招。5月21日,在备受瞩目的2026年度投资者日上,Spotify官方投下一枚重磅炸弹:正式宣布与全球最大的唱片公司环球音乐集团(UMG)达成里程碑式的战略授权协议。这项协议的核心直指如今最火热的粉丝生态——Spotify将允许Premium付费用户直接使用生成式AI技术,对他们喜爱的歌曲进行合法的翻唱(Covers)和二次混音(Remixes)。
这意味着,长期处于灰色地带的"AI换声翻唱"和"网易云/抖音式神级混音",首次被全球顶级音乐产业巨头正式"收编"为合法的商业产品。Spotify强调这套工具完全建立在"知情同意(Consent)、致敬署名(Credit)和合理报酬(Compensation)"的基础上,并将作为Spotify Premium的付费增值插件(Paid Add-on)推出,AI创作带来的收益将与参与该项目的艺术家及词曲作者进行直接分成。受此历史性合作及投资者日一系列AI战略的刺激,Spotify股价在宣布当天暴涨13%。
这次合作的字里行间,充斥着对Suno和Udio极具火药味的暗示。Spotify明确表示,其AI工具的开发原则是"先达成前端协议,而不是事后再寻求原谅"。就在不久前,各大唱片公司与AI音乐初创公司之间的版权大战刚经历了一轮惨烈洗牌:Suno最终向华纳音乐集团低头,达成了高达5亿美元的诉讼和解;Udio也陆续与环球音乐和华纳音乐达成了和解,目前仅剩索尼音乐的版权官司仍在拉锯。Spotify凭借自身无与伦比的流媒体霸主地位,选择直接绕过这一生态,去跟唱片公司建立纯正版的内生通道。
Spotify在投资者日上还公布了一连串足以重塑音频行业的AI核心产品线:大趣味模型(Large Taste Model)依托平台7.61亿活跃用户每天产生的3.4万亿条品味信号,用AI实时根据用户的语境、意图和习惯生成独一无二的流媒体界面;Studio by Spotify Labs是一款专为桌面端打造的独立应用,能连接用户的日历、收件箱等工具,利用AI自动为其量身定制个人播客、每日简报和专属歌单;此外还有AI语音克隆与播客工具、粉丝特权功能"Reserved"等。当用户在Spotify内部就能用几块钱一月的价格、合法且高保真地把一首泰勒·斯威夫特的情歌一键改造成硬核摇滚或电子蹦迪版,游离在版权边缘的Suno们,将不得不面对这场来自正版军团的终极降维打击。

拒绝彩排直接上舞台!美团LongCat-Video-Avatar1.5开源,全面击败主流闭源模型
美团龙猫大模型团队今日宣布,正式开源商用级数字人视频生成模型LongCat-Video-Avatar1.5。该版本实现了从开源SOTA(最高水平)向商业级实际应用的全面跨越,在唇形同步、物理合理性、长视频稳定性、多人互动及高效推理等核心维度上完成了全面跃升。
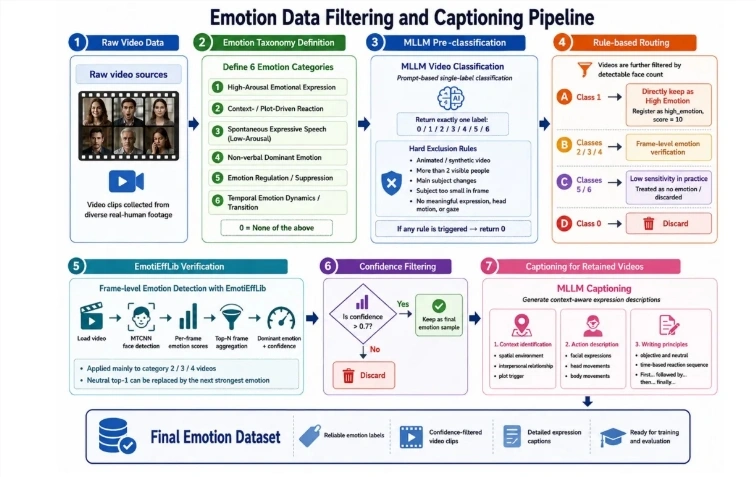
为了让数字人真正走向千人千面的真实应用场景,LongCat-Video-Avatar1.5针对传统数字人视频的"抖动、畸变、高延迟"等顽疾,进行了三大全方位升级。基础体验商用化方面,模型将音频特征提取编码器从Wav2Vec2升级为了Whisper-large,凭借更大的参数量和更丰富的多语言先验,模型能细致捕捉音素变化与发音节奏,使长句、快语速、歌唱等复杂音频下的唇动更精准,更实现了面部、头部、肢体动作与语音的自然协同,大幅减少了长视频中常见的跳帧和身份漂移。
强开放域泛化方面,团队构建了包含"离线标注"与"在线验证"的多阶段数据处理流程,并针对性注入了多人数据(利用主动说话人检测,消除多人场景下的音画歧义,准确区分说话者与聆听者)、静默数据(筛选未说话视频,让模型学习无语音状态下的自然微表情,避免非说话角色嘴部乱动)和情绪数据(结合帧级情绪识别精筛,注入情绪变化,使模型理解语音与表情的深层关联)。手部与连续性专项对齐方面,针对电商直播、产品展示等需要频繁露手的场景,模型引入了GRPO(人类偏好对齐),将奖励信号细化到逐帧层面,并加入首帧手部检测机制,显著缓解了手部畸变、局部结构崩塌以及动作不连贯等行业难题。
推理效率飙升15倍:商业级应用的另一大核心是成本。LongCat-Video-Avatar1.5采用了DMD(分布匹配蒸馏)技术,成功将原本需要50步的生成过程压缩至8步;同时,团队用"一个共享基础模型+多个LoRA适配器"的架构替代了传统的三模型并行方案,大幅释放显存。在实际测试中,模型实现了约15倍的推理效率提升,生成一段10秒的视频仅需约1分钟。
基于EvalTalker评测基准,770名评估者与10名领域专家对涵盖新闻、教育、娱乐等复杂场景的视频进行了结构化质量分析,数据显示LongCat-Video-Avatar1.5在多项核心指标上全面领先行业头部模型。
详情查看: https://www.aitop100.cn/infomation/details/33867.html
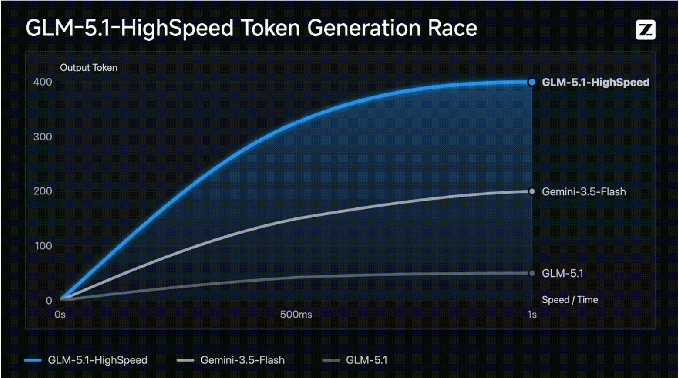
400tokens/s刷新全球纪录!智谱联合TileRT推出GLM-5.1高速版API
智谱今日正式面向部分企业客户推出GLM-5.1高速版API(GLM-5.1-highspeed)。该模型输出速度达到惊人的400tokens/s,成功刷新当前全球大模型厂商API的速度上限。这打破了行业过去"高性能模型必然带来高延迟"或"高速模型只能是轻量级模型"的惯例,GLM-5.1高速版首次在国产大模型中将旗舰级模型能力与极致低延迟同时带入生产环境,用户无需再为响应速度而牺牲模型质量。
在长程任务和复杂生产环境中,速度的提升带来了产品形态的质变。AI编程(Coding Agent)方面,在完整保留GLM-5.1强大能力的基础上,新模型实现"即问即答",模型能一边理解工程上下文,一边持续生成代码与修改方案,在需要数十轮调用的重构项目中,彻底消除了累计数分钟的空等。实时动态建模方面,在3D地图实测中,玩家控制角色移动并输入文字,模型能够瞬时完成建模并实时改变场景。Agent Swarm并行调度方面,在长程任务中,模型可在30秒内完成复杂网页处理,并能瞬间调度50个不同人格并行回答,展现出新型操作系统的雏形。
400TPS的稳定生产级能力,得益于智谱GLM团队与TileRT团队联合进行的系统级优化。推理引擎层(TileRT编译期AOT静态编排)方面,传统主流框架以算子(operator/kernel)作为基本调度单元,在单token、小batch场景下会放大调度、访存与同步开销;TileRT彻底抛弃了Runtime层的动态调度,在编译期(AOT)将整个计算图静态编排为一个常驻GPU的persistent Engine Kernel,在单卡内,计算、异步IO与通信被拆解为Tile级微任务,整个推理只Launch一次Kernel,中间结果通过寄存器、Shared Memory和L2 Cache直传,不再写回全局内存。调度系统层通过动态批处理、请求合并和KV缓存调度优化,显著降低了高并发场景下的尾延迟。基础设施层在多卡尺度上,TileRT将SM内部的Warp Specialization思路扩展到整张8卡NVL拓扑,不同GPU rank依据计算密度与数据依赖被特化为不同worker,配合网络链路与负载均衡协同优化,确保高性能的常驻稳定性。
详情查看: https://www.aitop100.cn/infomation/details/33866.html
字节跳动开源Lance 3B:用一个"脑子"同时搞定图视理解与生成
近日,字节跳动(ByteDance Research)正式开源了其原生统一多模态大模型Lance。在当前AI行业动辄堆砌数百亿甚至上万亿参数、或者靠"拼积木"组装大模型的风气下,Lance的出现无疑是一记重锤:它不仅以仅3B(30亿)的极致轻量化激活参数量实现了全功能覆盖,更是打破了长期以来"理解模型(VLM)"与"生成模型(DiT/Diffusion)"之间的技术高墙。
Lance的核心看点是"原生统一":拒绝"拼接",从零训练起就将图像/视频的理解、生成与跨模态编辑塞进同一个模型体系;全能跑通,单个模型完美闭环X→T(文/视理解)、X→I(图生成/编辑)、X→V(视频生成/编辑)三大核心输出任务;开源白嫖,采用极其友好的Apache 2.0协议,权重已全面上线Hugging Face,平民级128张A100算力预算即可跑通全程。
技术解密方面,Lance引入了极其精妙的"共享上下文+能力解耦并行"设计。所有文本、图像、视频输入进入模型前,首先会被打散并转化为统一的"交错序列",随后被送入双流专家架构(Dual-Stream MoE),让专门负责"理解"与"生成"的专家路由各司其职,完美解决能力冲突。理解侧,文本标记与视觉输入分别依赖Qwen2.5-VL的嵌入层与ViT编码器,精准提取高能语义视觉标记(Tokens);生成侧,视觉输入由Wan2.2强大的3D因果VAE压缩编码,实现16×空间下采样和4×时间下采样,保留最细腻的动态连续表示。Lance还独创了MaPE(模态感知旋转位置编码)机制,通过为不同模态组添加固定的时间偏移量,在不破坏图像和视频内部空间结构与时间顺序的前提下,让模型拥有了极强的空间和时间边界辨识力。
训练过程方面,相比于大厂动辄上万张卡闭眼烧钱的"暴力美学",Lance的训练过程展现了极高的"财务责任感"。整个生命周期被死死压在最多128张GPU预算内,通过4个环环相扣的阶段精细化推进:阶段1预训练(1.5T Tokens)狂啃1B图文对和140M视频文本对,打牢多模态底座;阶段2持续训练(300B Tokens)引入编辑、主体驱动生成、多模态理解数据,激活多任务协同效应;阶段3监督微调SFT(72B Tokens)疯狂注入人类指令,死磕指令遵循和视觉身份(ID)一致性;阶段4强化学习RL(GRPO算法)采用组相对策略优化,并罕见地搬出PaddleOCR作为奖励模型(Reward Model),针对性地暴击AI在图片中"文字渲染不准"以及"图文不对齐"的顽疾。
得益于跨任务的数据协同效应,3B体积的Lance在各项硬核基准测试中斩获了惊人的越级表现,Lance的开源对于整个生成式AI、尤其是当前火爆的AI短剧、智能体协作、互动媒体等赛道而言,是一场大象荡秋千般的产业降维打击。
开源地址: https://github.com/bytedance/Lance
制作效率提升80%!火山引擎上线「火山剧创1.0」,AI短剧进入工业化生产
近日,火山引擎正式发布了一站式AIGC短剧创作平台——「火山剧创1.0」。该平台深度适配火山引擎自研大模型,并依托多智能体(Multi-Agent)架构与火山方舟算力底座,旨在为专业短剧制作团队提供覆盖全生命周期的端到端解决方案。
「火山剧创1.0」不仅是一个生成工具,更是一套覆盖短剧生产全链路的智能工业系统。全链路覆盖方面,支持从剧本智能分析、角色与资产设定、分镜视频生成到成片实时预览,创作者在每个关键节点均拥有完全的编辑权限,确保内容创意的核心控制权始终掌握在人手中。极致效率提升方面,得益于多智能体架构的高效协同,平台可将短剧制作周期压缩80%以上,显著降低了从文字稿到视觉呈现的时间成本。强力算力支撑方面,底层由火山方舟提供算力支持,确保在处理海量视频生成任务时,平台依然能保持极高的稳定性与响应速度,满足影视级高清画质的实时渲染需求。
短剧产业正经历从"人力密集型"向"技术驱动型"的重大转型。火山引擎此次推出的平台,明确瞄准了当前短剧市场痛点:标准化协作,通过多智能体协同,将原本碎片化的制作流程标准化,不仅降低了新手门槛,也为专业影视公司提供了大规模生产的工业底座;创意可控性,不同于市面上部分"黑盒"式生成工具,火山剧创平台强调"全链路核心节点开放",这使得创作者能够在AI辅助生成的框架下,进行精准的视觉控制与叙事打磨,避免了AI生成内容的同质化与不可控。
目前,「火山剧创1.0」已面向短剧制作方开放使用。随着火山引擎在模型技术与底层算力设施上的持续投入,这一平台的上线预示着AI大模型在影视工业领域的落地已从"辅助实验"正式迈入"工业化生产"的新阶段。对于创作者而言,这意味着在"Agentic"时代,单人或小团队亦有能力打造电影级画质的短剧,内容创作的边际成本将进一步被拉平。
工具官网: https://s.c1ns.cn/jaPpy

CapCut与Gemini合作推出深度集成:AI创作工具实现智能互联
据CapCut官方消息,其正在与Google Gemini App展开合作。不久之后,用户将能够直接在Gemini应用内调用CapCut的高级创意和编辑功能,便捷地完成图像和视频的编辑工作。这一合作标志着创意工具间的进一步融合。
CapCut在推文中强调,双方此次合作旨在为用户打造更无缝、高效的AI创作体验,让专业级编辑能力触手可及。此次集成有望显著降低跨应用切换成本,让Gemini用户直接享受到CapCut强大的视频剪辑、智能特效、创意模板等功能,进一步推动AI工具在内容创作领域的普及与创新。CapCut表示,随着创意工作流程变得更加互联互通,未来的创作方式将更加对话化、直观化,并在各种工具和体验之间实现智能集成。“这仅仅是个开始。”
更多细节有待双方后续正式公布。从行业趋势来看,这次合作是AI创作工具生态整合的又一重要信号:用户不再需要在多个应用之间来回切换,而是可以在一个对话界面中完成从创意生成到精细编辑的全流程。CapCut的加入,也让Gemini的应用生态从"生成"走向"生成+编辑"的完整闭环。
详情查看: https://www.aitop100.cn/infomation/details/33868.html 
AITOP100-AI资讯频道将持续关注AI行业新闻资讯消息,带来最新AI内容讯息。
想了解AITOP100平台其它版块的内容,请点击下方超链接查看
AI创作大赛 | AI活动 | AI工具集 | AI资讯专区 | AI小说
AITOP100平台官方交流社群二维码:











